运行环境:
- vmware workstation
- ubuntu18.04
创建了三个docker容器,分别为master、slave1、slave2:
| 名称 | ip | hadoop/spark用户名 |
|---|---|---|
| master | 172.17.0.2 | spark |
| slave1 | 172.17.0.3 | spark |
| slave2 | 172.17.0.4 | spark |
三个容器都通过useradd创建了用户名为spark的用户,来配置集群大数据环境的用户。
Docker安装 #
安装docker-ce #
安装docker-ce:参考:https://mirrors.tuna.tsinghua.edu.cn/help/docker-ce/
#安装依赖
$sudo apt-get install apt-transport-https ca-certificates curl gnupg2 software-properties-common
# 信任Docker的GPG公钥
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add -
# 添加软件仓库
sudo add-apt-repository \
"deb [arch=amd64] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/debian \
$(lsb_release -cs) \
stable"
# 安装
sudo apt-get update
sudo apt-get install docker-ce
sudo systemctl start docker # 启动docker服务
sudo systemctl enable docker # 设置开机自启
配置docker仓库源 #
/etc/docker/daemon.json:
{
"registry-mirrors": [
"https://registry.docker-cn.com"
]
}
之后重新加载daemon和重启docker:
$sudo systemctl daemon-reload
$sudo systemctl restart docker
获得ubuntu镜像 #
因为我的主机系统是ubuntu18.04,所以需要pull ubuntu18.04的镜像
$sudo docker pull ubuntu:18.04
18.04: Pulling from library/ubuntu
d519e2592276: Pull complete
d22d2dfcfa9c: Pull complete
b3afe92c540b: Pull complete
Digest: sha256:ea188fdc5be9b25ca048f1e882b33f1bc763fb976a8a4fea446b38ed0efcbeba
Status: Downloaded newer image for ubuntu:18.04
docker.io/library/ubuntu:18.04
$
容器操作 #
创建并启动容器 #
以slave1为例,说明创建容器和配置容器的内容和流程,master和slave2同slave1。
根据ubuntu18.04创建容器,并命名为slave1
ubuntu# docker run -itd --name slave1 ubuntu:18.04 #还可以指定很多参数、例如ip、hostname等,参照docker命令语法
c7f88304681bc8a600091911bd57d5f63f5eb03d8f3baeda464aa2b1d304d8f0
ubuntu# docker exec -it slave1 bash
root@c7f88304681b:/#
安装一些必备软件(默认docker容器中没有携带sudo、ifconfig、vim等命令和应用):
root@c7f88304681b:/# passwd # 配置root密码
Enter new UNIX password:slave1root
Retype new UNIX password:slave1root
passwd: password updated successfully
root@c7f88304681b:/# apt update
root@c7f88304681b:/# apt install vim wget net-tools iputils-ping ssh sudo
新建用户spark、和用户组spark、并为spark用户添加sudo权限
root@c7f88304681b:/# groupadd -g 1000 spark
root@c7f88304681b:/# useradd -u 2000 -g spark -m -s /bin/bash spark # -m表示自动创建用户家目录/home/spark、并指定默认的登录shell为bash
root@c7f88304681b:/# passwd spark #给spark用户设置密码
root@c7f88304681b:/# usermod -G sudo spark #为spark用户添加sudo权限
之后我们可以spark用户登录到slave1容器中:
ubuntu# docker exec -it --user=spark slave1 bash
spark@c7f88304681b:~$
开启ssh服务:
root@c7f88304681b:/# /etc/init.d/ssh start
编辑/etc/ssh/sshd_config, 允许公钥登录
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
然后将master和slave1、slave2的公钥都放入authorized_keys中,分发到三个系统的~/.ssh/目录下,即可互相之间免密码登录:
#演示免登录
spark@master $ ssh spark@slave1
Welcome to Ubuntu 18.04.5 LTS (GNU/Linux 5.4.0-62-generic x86_64)
.....
Last login: Sun Jan 24 09:20:10 2021 from 172.17.0.1
$
# ....
spark@master $ ssh spark@slave2
Welcome to Ubuntu 18.04.5 LTS (GNU/Linux 5.4.0-62-generic x86_64)
.....
Last login: Sun Jan 24 09:20:18 2021 from 172.17.0.1
$
为了达到上面的登录时,不用输入ip的目的,还需要在/etc/hosts文件中添加以下ip和名称的映射关系
172.17.0.2 master
172.17.0.3 slave1
172.17.0.4 slave2
容器中安装hadoop、spark #
在用户主机上执行(自行下载jdk、maven、scala、hadoop、spark等安装包):
# 将安装包从用户主机复制到master、slave1和slave2中
$sudo docker cp ./OpenJDK8U-jdk_x64_linux_hotspot_8u275b01.tar.gz slave1:/app/soft/
$sudo docker cp ./hadoop-3.3.0.tar.gz slave1:/app/soft/
$sudo docker cp ./spark-3.0.1.tgz slave1:/app/soft/
登录slave1:安装jdk、hadoop、spark
spark@slave1:/app/soft$ tar -xvzf OpenJDK8U-jdk_x64_linux_hotspot_8u275b01.tar.gz
spark@slave1:/app/soft$ tar -xvzf hadoop-3.3.0.tar.gz
spark@slave1:/app/soft$ tar -xvzf spark-3.0.1.tgz
配置环境变量,~/.bashrc中添加:
export JAVA_HOME=/app/soft/jdk8u275-b01
export HADOOP_HOME=/app/soft/hadoop-3.3.0
export YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/conf
export CLASSPATH=${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export SPARK_HOME=/app/soft/spark-3.0.1
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH
配置文件 #
- hadoop-env.sh 环境变量(指定JAVA_HOME)
- core-site.xml、hdfs-site.xml
- yarn-site.xml、mapre-site.xml、capacity-scheduler.xml
- log4j.properties 日志
hdfs #
# hadoop-env.sh
export JAVA_HOME=/app/soft/jdk8u275-b01
<!-- core-site.xml -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/tmp/spark</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
<!-- hdfs-site.xml -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/tmp/spark/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/tmp/spark/dfs/data</value>
</property>
</configuration>
yarn #
<!-- yarn-site.xml -->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
# workers
slave1
slave2
spark #
spark配置较简单,配置两个文件即可使用:spark-env.sh、slaves。
/app/soft/spark-3.0.1/conf/spark-env.sh:
export JAVA_HOME=/app/soft/jdk8u275-b01
export SPARK_HOME=/app/soft/spark-3.0.1
export HADOOP_HOME=/app/soft/hadoop-3.3.0
export HADOOP_CONF_DIR=/app/soft/hadoop-3.3.0/conf
export SPARK_DIST_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath)
export SPARK_LOCAL_IP=172.17.0.2
export SPARK_MASTER_IP=master
export SPARK_MASTER_HOST=172.17.0.2 # HOST在启动slaves时会用到,不配置会启动不了worker
export SPARK_MASTER_PORT=7077
export SPARK_EXECUTOR_INSTANCES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=128M # 每个worker的内存配置为128M
export SPARK_MASTER_WEBUI_PORT=8080
export SPAKR_CONF_DIR=/app/soft/spark-3.0.1/conf
/app/soft/spark-3.0.1/conf/slaves:
master
slave1
slave2
运行启动 #
启动hdfs(namenode、datanode):
spark@4d0d1b1c25a0:~$ start-dfs.sh
Starting namenodes on [master]
Starting datanodes
Starting secondary namenodes [4d0d1b1c25a0
打开浏览器:http://master:9870即可看到:
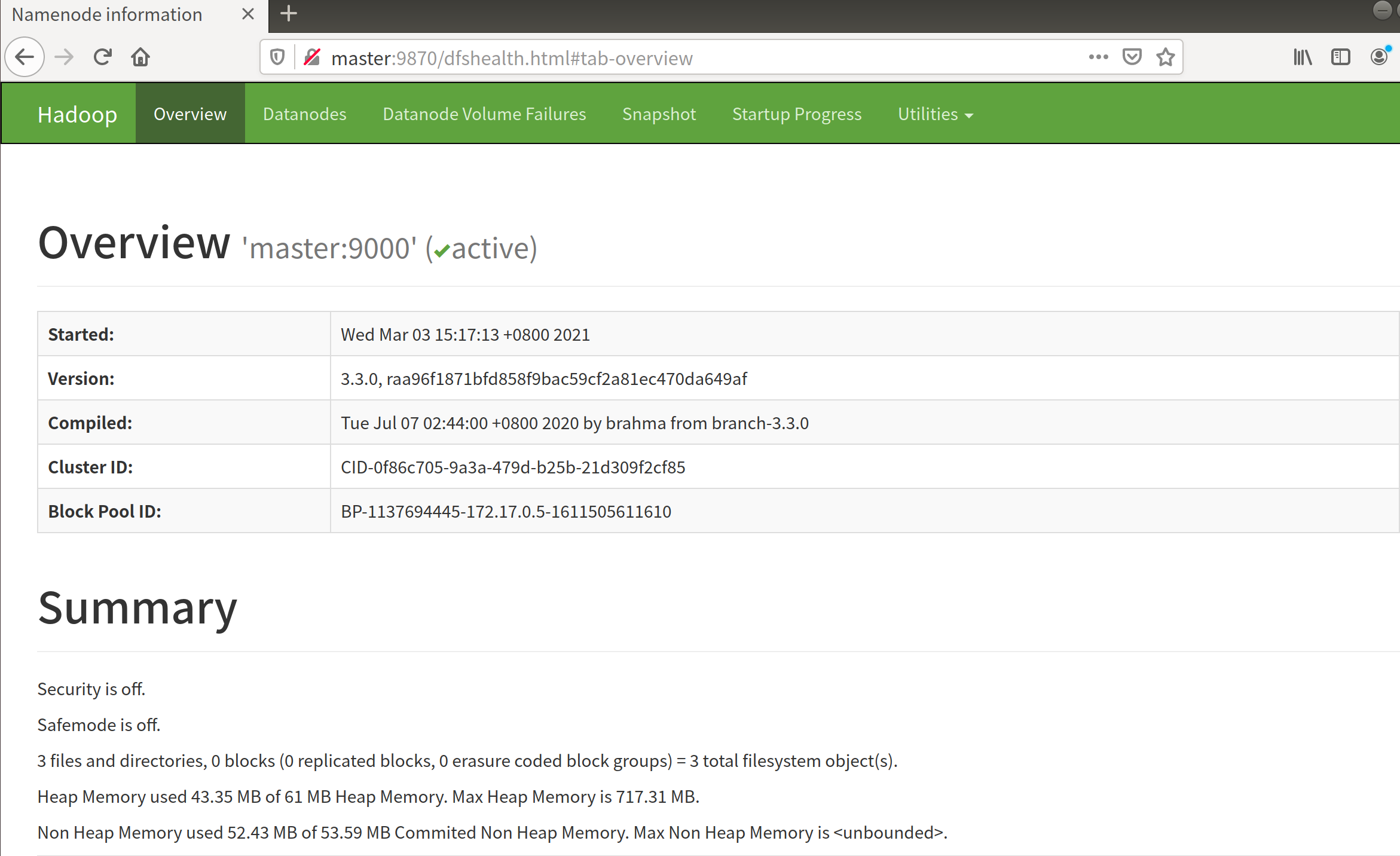
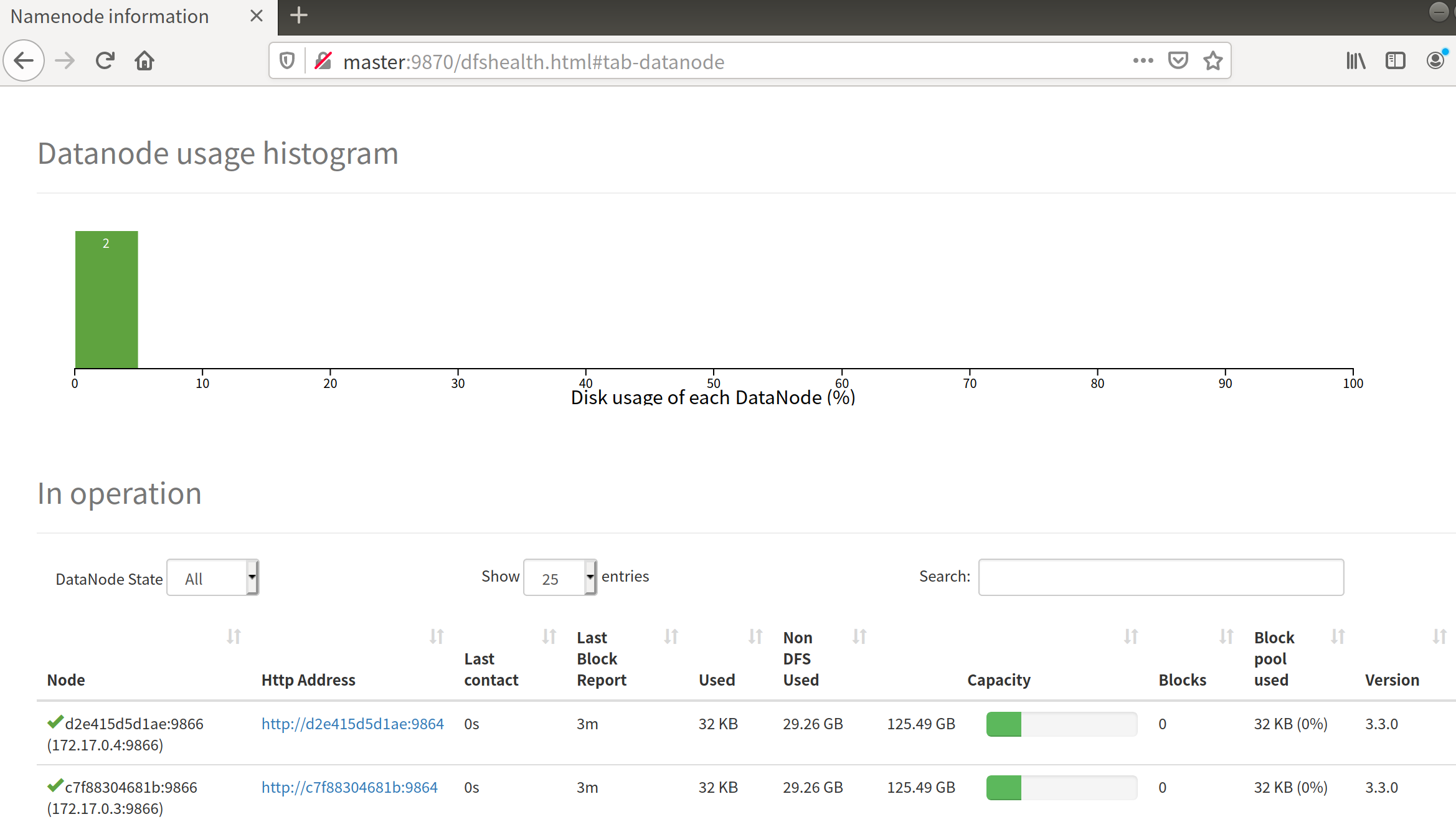
启动yarn:
spark@4d0d1b1c25a0:~$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
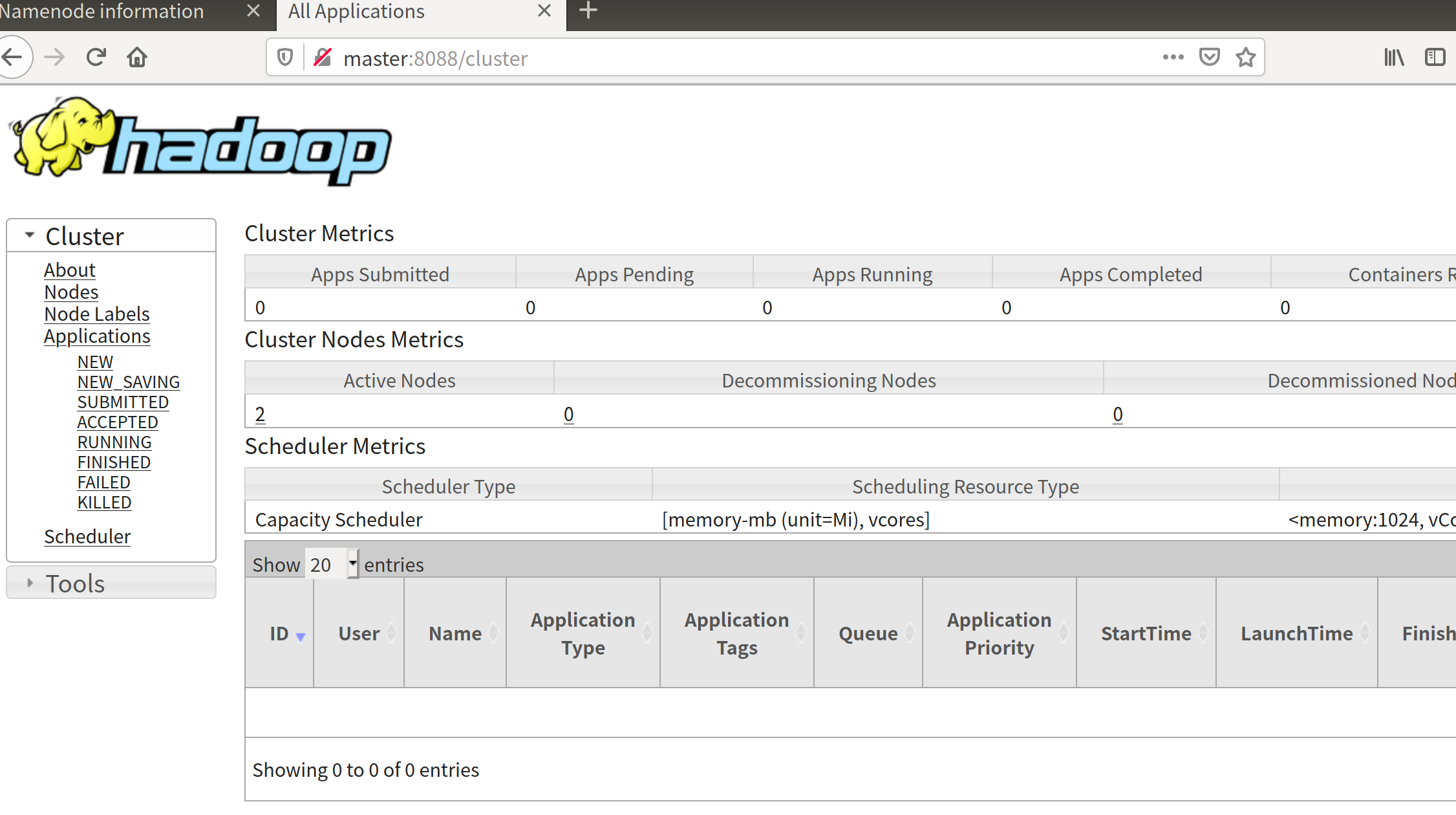
启动spark:
spark@4d0d1b1c25a0:~$ start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /app/soft/spark-3.0.1/logs/spark--org.apache.spark.deploy.master.Master-1-4d0d1b1c25a0.out
spark@4d0d1b1c25a0:~$ start-slaves.sh
slave1: starting org.apache.spark.deploy.worker.Worker, logging to /app/soft/spark-3.0.1/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-c7f88304681b.out
slave2: starting org.apache.spark.deploy.worker.Worker, logging to /app/soft/spark-3.0.1/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-d2e415d5d1ae.out
master: starting org.apache.spark.deploy.worker.Worker, logging to /app/soft/spark-3.0.1/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-4d0d1b1c25a0.out
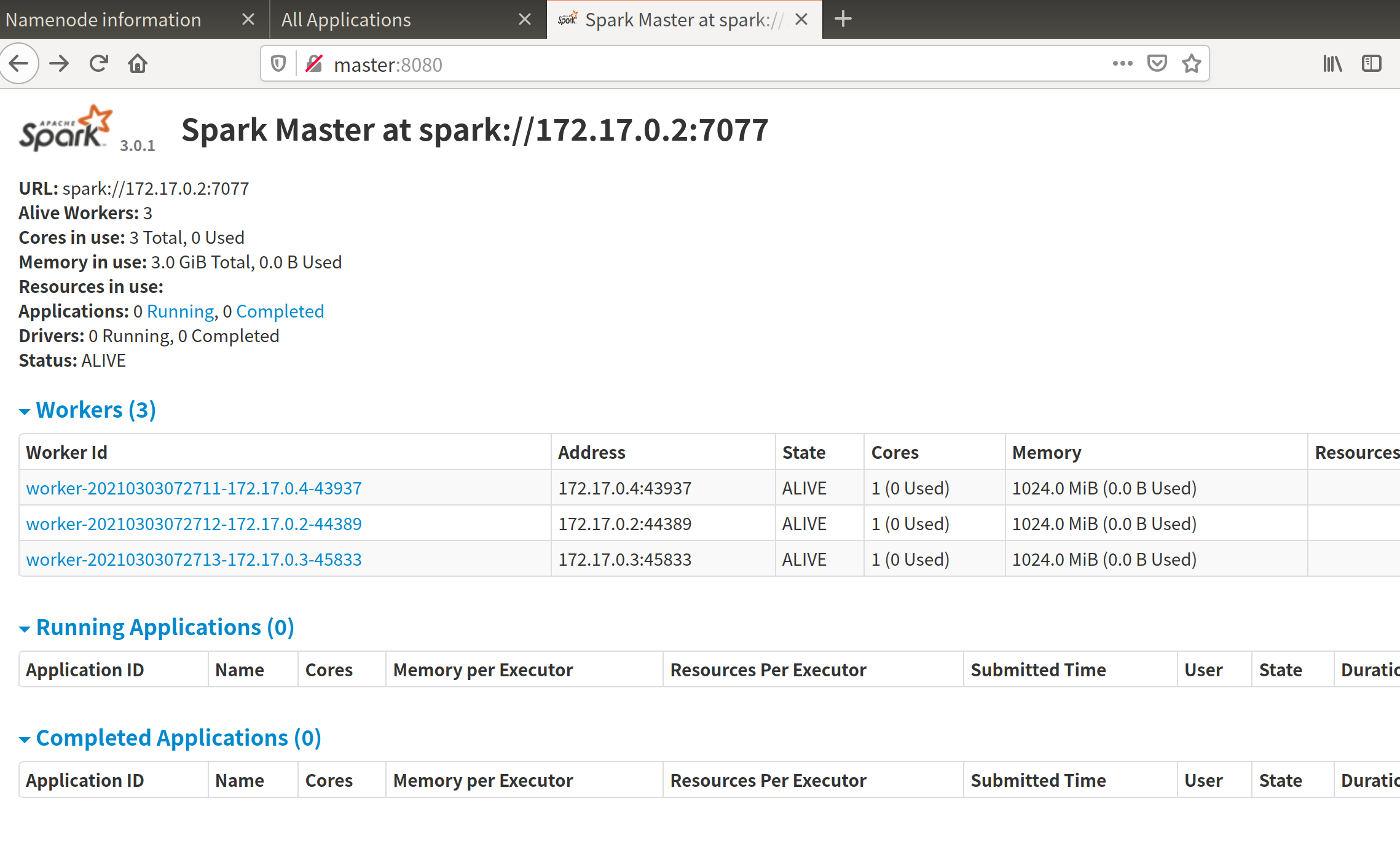
顺便我们也可以在我们的master和slave上运行jps查看jvm中的进程:
# master上运行jps
spark@4d0d1b1c25a0:~$ jps
1648 Worker
1699 Jps
1127 ResourceManager
647 NameNode
1482 Master
847 SecondaryNameNode
# slave1上运行jps
spark@c7f88304681b:/$ jps
465 Worker
178 DataNode
291 NodeManager
525 Jps
其余参考 #
配置ubuntu源 #
ubuntu自带的apt源下载应用速度过慢,可以使用tsinghua、163、或者aliyun的源,这里以aliyun的源为例:
spark$ su
root# mv /etc/apt/sources.list /etc/apt/sources.list.bak
root# touch /etc/apt/sources.list
编辑sources.list文件内容为:
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
之后别忘记apt update以下,就可以使用apt install 愉快的安装应用了。
docker命令 #
由于docker是运行在用户主机上的,所以用户主机关机后,docker中的容器也会自动关掉。
可以通过docker container restart slave1命令启动slave1容器
$ sudo docker container restart slave1
linux操作 #
查看当前机器名称:
spark@4d0d1b1c25a0:/$ cat /etc/hostname
4d0d1b1c25a0