translate from: http://llvm.org/docs/tutorial/LangImpl03.html
介绍四个基本表达式和函数申明与定义的Codegen.
3.1 Chapter 3 Introduction #
本章将会向你介绍如何转换为AST. built in Chapter2, into LLVM IR. 这将会教给你a little bit about LLVM是如何做这个的. 以及展示它的实用性. 构建一个词法分析器和解析器要比生成LLVM IR代码的工作多得多.
please note: 本章和之后的代码是基于LLVM 3.7 and later. LLVM 3.6 和之前的版本将不会工作for this code. 也要注意, 你需要一个匹配你的LLVM Release版本的tutorial.
3.2 Code Generation Setup #
为了产生LLVM IR, 我们想要一些简单的setup来start. 首先我们定义virtual code generation(codegen)方法在每一个AST类中.
/// ExprAST - Base class for all expression nodes.
class ExprAST {
public:
virtual ~ExprAST() {}
virtual Value *codegen() = 0;
};
/// NumberExprAST - Expression class for numeric literals like "1.0".
class NumberExprAST : public ExprAST {
double Val;
public:
NumberExprAST(double Val) : Val(Val) {}
virtual Value *codegen();
};
codegen()表示为AST节点依赖它们来产生IR , 并且他们都返回一个Value对象(被用来表示"Static Single Assigment(SSA) register" or “SSA value"in LLVM).
SSA值的最独特的方面是当相关指令执行时, 他们的值被计算. 并且在指令再次执行之前, 它不会获得新值. 换句话说, 没有方法来改变SSA值. 为了了解更多关于SSA的信息, please read up on Static Single Assignment - 一旦你理解了它, the concepts are really quite natural.
请注意, 不是将虚方法添加到ExprAST的类层次结构中, 使用访问者模式或者其他方式对此进行建模也是有意义的.
Again, 本教程将不再讨论良好的软件工程实践: 出于我们的目的, 添加虚拟方法是最简单的.
我们想要的第二件事情, 是像我们在编写解析器时那样, 当发生错误时报告error. (例如, 对一个未声明参数的使用).
static LLVMContext TheContext;
static IRBuilder<> Builder(TheContext);
static std::unique_ptr<Module> TheModule;
static std::map<std::string, Value *> NamedValues;
Value *LogErrorV(const char *Str) {
LogError(Str);
return nullptr;
}
在代码产生阶段, 静态变量将会被使用. TheContext 是一个掌握了大量的核心LLVM data 结构不透明的对象, 例如the type and 常量value tables. 我们不必关注它的细节, 我们仅仅需要一个简单的实例, 直接将它传到我们需要的API中即可.
The Builder object 帮助我们使产生IR这件事变得很容易. IRBuilder类的实例模板来跟踪当前插入指令的位置并且提供创建新指令的方法.
TheModule 是一个LLVM construct(包含函数和全局变量). In many ways, 它是一个LLVM IR用于包含代码的顶级结构.它将会掌控我们产生的IR的内存 (这就是为什么 codegen() method返回一个raw value*, 而不是unique_ptr
The NamedValues map 会跟踪当前作用域中定义的值以及它们的LLVM表示形式. (换句话说, 它是代码的符号表). 在 Kaleidoscope的形式中, 能被引用的唯一的things 是函数参数. 因此, 当为函数体进行Codegen时, 函数参数将会存在于该map中.
有了这些基础知识, 我们可以开始讨论如何为每个表达式 generate code. 注意: this 假定已经设置了Builder来生成代码. 现在, 我们假设已经完成了, 我们将会just 用它来emit code.
3.3 Expression Code Generation #
为每一个表达式产生LLVM code是非常直接的.
numExpr #
First we’ll do numberic literals:
Value *NumberExprAST::codegen() {
return ConstantFP::get(TheContext, APFloat(Val));
}
在LLVM IR中, 数字常量用ConstantFP类来表示, (在内部保存APFloat的值)( APFloat 具有保存任意精度的浮点常数的能力). 这段代码基本就是创建并返回了一个ConstantFP. 注意 在LLVM IR中, 常量都是唯一的, 并且被共享. 出于这个原因, The API use the “foo::(..)“而不是 “new foo(…)” or “foo::Create(..)”.
VariableExpr #
Value *VariableExprAST::codegen() {
// Look this variable up in the function.
Value *V = NamedValues[Name];
if (!V)
LogErrorV("Unknown variable name");
return V;
}
使用LLVM对变量的引用也非常简单. 在我们simple Kaleidoscope中, 我们假定变量已经被emitted somewhere 并且它的值是可用的. 实际上, In the namedValues map 的唯一的值是函数参数. 此代码只是检查指定的name是否在map中. (如果没有, 未知变量将会被引用) 并且返回value for it. 在未来的章节, we’ll 将会在符号表和局部变量中增加Loop Induction variables (可以阅读第5章: 对 Loop 进行 codegen的部分).
BinaryExprAST #
Value *BinaryExprAST::codegen() {
Value *L = LHS->codegen();
Value *R = RHS->codegen();
if (!L || !R)
return nullptr;
switch (Op) {
case '+':
return Builder.CreateFAdd(L, R, "addtmp");
case '-':
return Builder.CreateFSub(L, R, "subtmp");
case '*':
return Builder.CreateFMul(L, R, "multmp");
case '<':
L = Builder.CreateFCmpULT(L, R, "cmptmp");
// Convert bool 0/1 to double 0.0 or 1.0
return Builder.CreateUIToFP(L, Type::getDoubleTy(TheContext),
"booltmp");
default:
return LogErrorV("invalid binary operator");
}
}
二元操作符开始变得有趣.
这里的基本思想: 我们递归地为表达式的左侧emit code, 然后是右侧, 然后我们计算二进制表达式的结果. 在这个代码中, 我们做一个简单的switch on the opcode来创建正确的LLVM 指令.
在上面的例子中, LLVM Builder类开始显示其值. IRBuilder知道在哪里插入新创建的指令, 你所做的就是要指定什么指令将会被创建 (例如, 使用 CreateFAdd), which 使用哪些操作数(L and R here) 并且optionally 为生成的指令提供一个名字.
关于LLVM, 一个不错的事情是名称就像一个提示. 例如, 如果上面的代码emit 多条 “addtmp” 变量, LLVM将自动地为每个变量提供一个递增的, 独特的数字suffix(后缀). 指令的本地值名称purely可选择的, but 它的名称应该要更方便我们阅读.
LLVM 指令是被严格的规则所限制: For Example, 一个指令的左边和右边的操作符一定要有相同的类型, 并且add的结果类型一定要匹配操作数类型. 因为in Kaleidoscope所有的值都是doubles, this makes for very simple code for add, sub, mul.
在另一方面, LLVM 指定 fcmp 指令总是返回一个 “i1” 值( 1 比特整型). 问题是 Kaleidoscope希望值是0.0或者1.0. 为了获得这些语义, 我们将fcmp指令与uitofp指令(unsigned integer to float point)结合起来. 该指令通过将它的输入整数转换为浮点值by 将输入视为无符号值. 相反, 如果我们使用sitofp指令, The kaleidoscope ‘<’ 操作符将会返回0.0和**-1.0**, 具体依赖于输入值.
CallExprAST #
Value *CallExprAST::codegen() {
// Look up the name in the global module table. 在全局module table中寻找name
Function *CalleeF = TheModule->getFunction(Callee);
if (!CalleeF)
return LogErrorV("Unknown function referenced");
// If argument mismatch error.
if (CalleeF->arg_size() != Args.size())
return LogErrorV("Incorrect # arguments passed");
std::vector<Value *> ArgsV;
for (unsigned i = 0, e = Args.size(); i != e; ++i) {
ArgsV.push_back(Args[i]->codegen());
if (!ArgsV.back())
return nullptr;
}
return Builder.CreateCall(CalleeF, ArgsV, "calltmp");
}
使用LLVM来产生函数调用的codegen是相当简单直接的.
上面的代码最开始会在LLVM Module’s 符号表中 寻找函数的名称. 回想一下, LLVM Module是一个可以包含我们正在执行的JIT函数的容器. 通过给每一个函数指定与用户指定的相同的名称, 我们可以使用LLVM 符号表来解析我们的函数名称.
一旦我们有函数要调用, 我们递归地codegen(编码)每一个我们要传入的参数, 并且创建一个LLVM调用指令. 注意, LLVM默认使用本地的c调用规定, 允许这些调用来调用标准库函数(like “sin” and “cos”)是轻松的, 不需要任何额外的工作.
这包含了我们对四个基本表达式(in Kaileidoscope)的处理. 当然, 你可以随意添加更多. 例如, 通过浏览 LLVM Language reference. 你将会找到其他一些有趣的指令, 并且将他们加到我们的框架中是非常简单的.
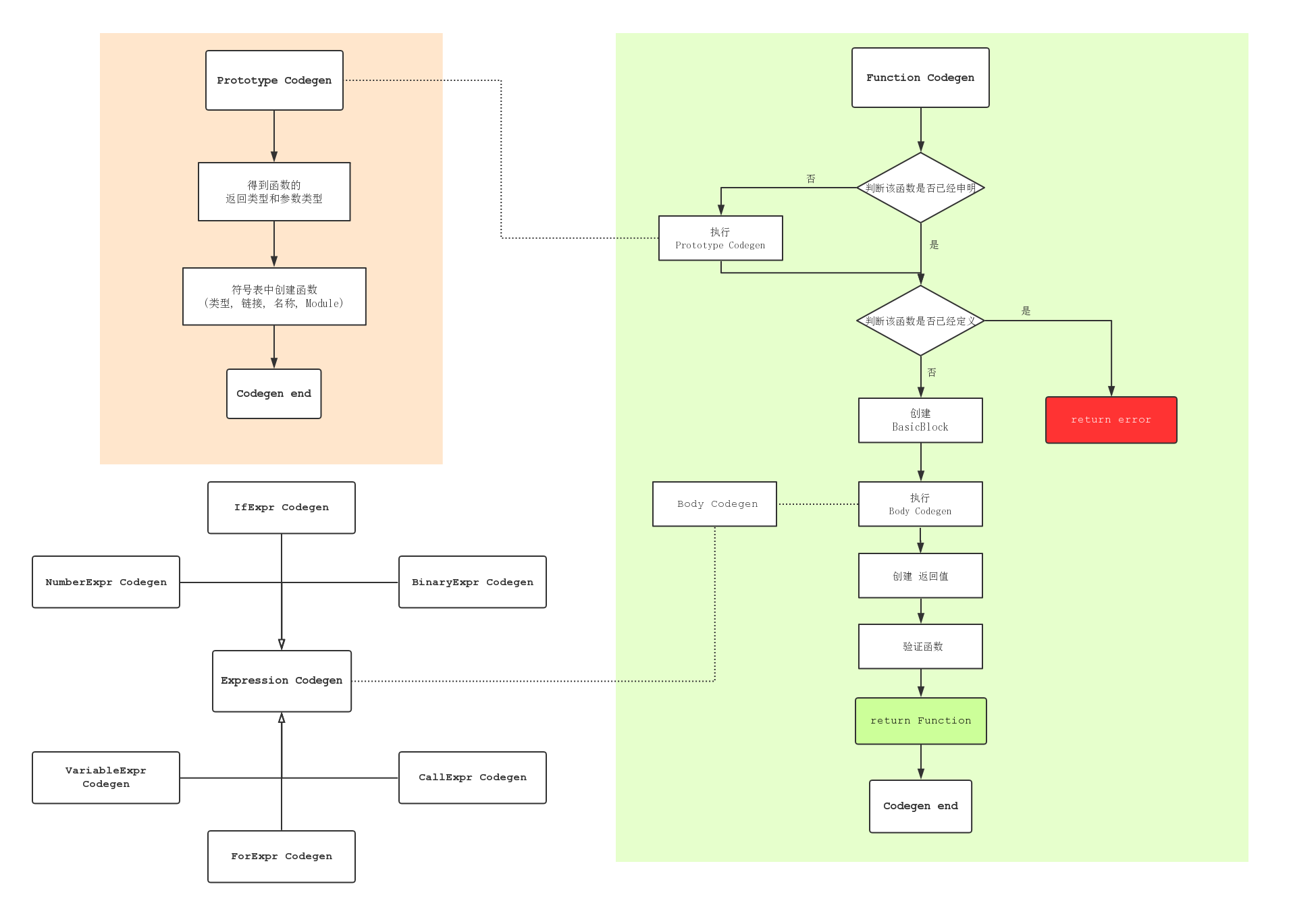
3.4 Function Code Generation #
函数申明和函数定义的代码生成要处理大量的细节, which 这使得它们的代码生成不如expression 的代码生成 漂亮, but 这允许我们说明一些重要的点.
PrototypeAST #
首先, 我们先讨论函数申明的代码产生: 他们可以用于函数体, 也可以用于外部函数申明.
The code starts with:
Function *PrototypeAST::codegen() {
// Make the function type: double(double,double) etc.
std::vector<Type*> Doubles(Args.size(),
Type::getDoubleTy(TheContext));
FunctionType *FT =
FunctionType::get(Type::getDoubleTy(TheContext), Doubles, false);
Function *F =
Function::Create(FT, Function::ExternalLinkage, Name, TheModule.get());
这段代码将大量的功能集成到几行. First注意, 这个函数返回了一个”Function“而不是”Value”. 因为"prototype"是在讨论函数的外部接口(而不是表达式计算的值), 当codegen时, 返回LLVM Function是有意义的.
FunctionType::get的调用创建FunctionType(that 被用于给定的声明). 由于Kaleidoscope中所有的函数参数都是double类型的, 第一行创建了一个"N个double类型的vector”. 然后使用FunctionType::get创建了接收N个double类型参数的函数. 返回一个double作为结果,(那不是可变参数(false表示这一点)). 注意 LLVM中类型是和常量一样唯一的, 所以你不用"new a type", you “get” it.
上面的最后一行实际上创建了与Prototype相对应的IR函数. 这表明了要使用的类型, 链接, 名称, 以及要插入的模块. “external linkage"意味着该函数可能在当前模块之外定义. and or 它能够被模块外面的函数所调用. 传入的名称是用户指定的名称: 由于指定了"TheModule”, 因此该名称在"TheModule"符号表中被注册.
// Set names for all arguments. 设置所有参数的名称
unsigned Idx = 0;
for (auto &Arg : F->args())
Arg.setName(Args[Idx++]);
return F;
最后, 我们根据Prototype中的名称设置每个函数参数的名称. 这一步并不是严格需要的, 但是保持名称的一致是IR的可读性更强, 并允许后面的代码直接引用其名称的参数, 而不需要在PrototypeAST中查找他们.
FunctionAST #
我们有一个没有函数体的function prototype. 这是LLVM IR表示函数申明的方式. 对于在Kaileidoscope中的extern表达式来说, 这正是我们想要表达的. 然而对于函数定义来说,我们需要codegen并且attach a 函数体:
Function *FunctionAST::codegen() {
// First, check for an existing function from a previous 'extern' declaration.
Function *TheFunction = TheModule->getFunction(Proto->getName());
if (!TheFunction)
TheFunction = Proto->codegen();
if (!TheFunction)
return nullptr;
if (!TheFunction->empty())
return (Function*)LogErrorV("Function cannot be redefined.");
对于函数定义来说, 我们首先在TheModule的符号表中搜索此函数的现有版本.
- 一种case是:using “extern” 语句时, 符号表就被创建了. 如果 Module::getFunction 返回 null, 则意味着不存在先前的版本, 所以我们就需要根据申明来进行Prototype Codegen.
- 在另一种case中, 我们想要在我们开始之前, assert函数是empty(i.e. 还没有函数体)
// Create a new basic block to start insertion into. 创建一个新的basic block 来插入.
BasicBlock *BB = BasicBlock::Create(TheContext, "entry", TheFunction);
Builder.SetInsertPoint(BB);
// Record the function arguments in the NamedValues map. 在NamedValue mao中记录函数参数.
NamedValues.clear();
for (auto &Arg : TheFunction->args())
NamedValues[Arg.getName()] = &Arg;
现在我们可以开始建立Builder了:
第一行创建了一个new basic block(named “entry”), 被直接插入到函数中. 第二行告诉我们新的指令应该被插在new basic block的末尾. 在LLVM中Basic Block(define the Control Flow Graph)是函数中重要的一部分. 因为我们没有任何控制流, 所以此时我们的函数只包含一个Block. we’ll fix this in Chapter 5.
现在我们添加函数参数到NamedValues map中(当然了, 首先它会被清空) 以便于它们可以被VariableExprAST节点所获取.
if (Value *RetVal = Body->codegen()) {
// Finish off the function.
Builder.CreateRet(RetVal);
// Validate the generated code, checking for consistency.
verifyFunction(*TheFunction);
return TheFunction;
}
- 一旦在设置了插入点, 并且填充了NamedValues之后, 我们调用codegen() 方法作为function的 root 表达式.
- 如果没有error发生, this emits code计算表达式到 entry block 并返回计算出的值.
- 假设没有error, 我们然后创建an LLVM ret instruction (表示函数完成).
- 一旦函数被构建后, 我们就会调用verifyFunction(which provided by LLVM). 该函数对产生的IR做大量的一致性检测, 来确定是否我们的编译代码都是正确的. 使用它是相当重要地, 它能够捕获大量的bugs. 一旦一个函数完成并验证后, 我们就会返回它.
// Error reading body, remove function.
TheFunction->eraseFromParent();
return nullptr;
}
最后剩下的唯一一件事情就是处理error case. 简单起见, 我们仅仅通过使用earseFromParent方法来删除我们Codegen的函数. 这允许用户重新定义他们之前输入错误的函数: 如果我们不删除它, 它将会继续保存在符号表中, 并且它还有body, 阻止我们之后定义.
这代码有一个bug, 如果**FunctionAST::codegen()**方法发现了一个存在的IR Function. 它不会根据自己的申明来验证其签名. 这意味着: 一个更早的extern申明将会优先于函数定义的签名, 这可能导致codegen失败. 例如, 如果函数参数的名称不同.(what means ? 以后再研究)
有很多方法可以解决这个问题, see what you can come up with! Here is a testcase:
extern foo(a); # ok, defines foo.
def foo(b) b; # Error: Unknown variable name. (decl using 'a' takes precedence).
3.5 Driver Changes and Closing Thoughts #
到目前为止, 除了我们可以查看漂亮的LLVM调用之外, LLVM的Codegen并没有给我们带来太多的帮助. The sample code 将对codegen的调用插入到 “HandleDefinition”, “HandleExtern"等函数中, 然后dump out the LLVM IR.
这里有一个简单的方法来查看LLVM IR. Ex:
ready> 4+5;
Read top-level expression:
define double @0() {
entry:
ret double 9.000000e+00
}
注意 解析器是如何将顶级表达式转换为我们的anonymous函数. 当我们在下一章添加JIT Support时, 这会很便利.
另外, 代码是literally transcribed, 除了IRBuilder会进行简单的常量折叠外, 不会执行任何优化. 下一章, 我们将会添加一些隐式地优化.
ready> def foo(a b) a*a + 2*a*b + b*b;
Read function definition:
define double @foo(double %a, double %b) {
entry:
%multmp = fmul double %a, %a
%multmp1 = fmul double 2.000000e+00, %a
%multmp2 = fmul double %multmp1, %b
%addtmp = fadd double %multmp, %multmp2
%multmp3 = fmul double %b, %b
%addtmp4 = fadd double %addtmp, %multmp3
ret double %addtmp4
}
这里展示了一些简单的表达式运算.
ready> def bar(a) foo(a, 4.0) + bar(31337);
Read function definition:
define double @bar(double %a) {
entry:
%calltmp = call double @foo(double %a, double 4.000000e+00)
%calltmp1 = call double @bar(double 3.133700e+04)
%addtmp = fadd double %calltmp, %calltmp1
ret double %addtmp
}
这里展示了一些函数调用.
Note 如果你调用它的话, 这个函数将会花大量时间来执行.
在未来, 我们将会添加一些条件控制流来使递归变得可以使用.
ready> extern cos(x);
Read extern:
declare double @cos(double)
ready> cos(1.234);
Read top-level expression:
define double @1() {
entry:
%calltmp = call double @cos(double 1.234000e+00)
ret double %calltmp
}
这里展示了一个extern for libm “cos” 函数, and call to it:
ready> ^D
; ModuleID = 'my cool jit'
define double @0() {
entry:
%addtmp = fadd double 4.000000e+00, 5.000000e+00
ret double %addtmp
}
define double @foo(double %a, double %b) {
entry:
%multmp = fmul double %a, %a
%multmp1 = fmul double 2.000000e+00, %a
%multmp2 = fmul double %multmp1, %b
%addtmp = fadd double %multmp, %multmp2
%multmp3 = fmul double %b, %b
%addtmp4 = fadd double %addtmp, %multmp3
ret double %addtmp4
}
define double @bar(double %a) {
entry:
%calltmp = call double @foo(double %a, double 4.000000e+00)
%calltmp1 = call double @bar(double 3.133700e+04)
%addtmp = fadd double %calltmp, %calltmp1
ret double %addtmp
}
declare double @cos(double)
define double @1() {
entry:
%calltmp = call double @cos(double 1.234000e+00)
ret double %calltmp
}
当你退出demo时(在 linux 上通过CTRL+D,or windows上通过CTRL+Z来发送EOF), 它将会显示该module产生的所有IR.
这就是Kaleidoscope tutorial 第三章的内容.
接下来, 我们会展示如何添加JIT Codegen和优化器支持, 以便于我们之后可以开始运行代码.