translate from: http://llvm.org/docs/tutorial/LangImpl05.html
本文为Kaleidoscope添加条件判断控制流和循环控制流.
注意: 本文假定你已经阅读过前面几篇文章, 所以在词法解析和AST生成就写的比较简单(当然了, 这部分内容本身阅读起来就比较轻松), 着重介绍控制流的Codegen部分.
因为这个系列主要是翻译, 所以基本没有涉及自己的理解. 之后我会单独写一篇文章, 来对Kaleidoscope的前五章做一个总结.
Chapter 5 Introduction #
Welcome to Chapter 5 of the “Implementing a language with LLVM " tutorial.
第一章到第四章描述了Kaleidoscope的简单的实现并且支持了LLVM IR的生成, 然后是优化和JIT编译器.
不幸地是, 正如你现在现在看到的, Kaleidoscope 是几乎无用的:
除了调用和返回之外, 它没有其他控制流. 这意味着你在代码中没有条件分支, 从而限制了它的功能.
在本期 构建编译器中, 我们将会扩展Kaleidoscope, 使它拥有 if/then/else表达式和一个简单的 for 循环.
if/Then/Else #
扩展Kaleidoscope来支持if/then/else是相当直接的. 它基本上就是为词法分析器, 解析器, AST, LLVM Code emitter增加新的概念.
例子是很不错的, 因为它表明了随着时间的推移, 根据新的概念来对语言进行扩展是多么的容易.
在我们进行扩展之前, 让我们讨论一下我们到底想要做什么.
基本的意思是我们想要能够写出这样的代码:
def fib(x)
if x < 3 then
1
else
fib(x-1)+fib(x-2);
在Kaleidoscope中, 每个构造都是一个表达式: 没有语句. 因此, if/then/else 表达式需要像其他表达式一样返回值. 由于我们正在使用一个普遍的功能形式, 我们会计算它的条件, 然后根据条件的解析方式返回 then或else值.
if/then/else的表达式的语义是: 它能够将条件计算为一个bool等价的值: 0.0被认为是false, everything else被认为是true. 如果条件为true, 则计算并返回第一个子表达式值; 如果条件为false, 则计算并返回第二个表达式值. 由于Kaleidoscope 允许产生副作用, 所以将该行为确定下来是非常重要的.
现在我们知道了我们想要做什么, 下面让我们一起了解它的组成部分.
if/then/else的Lexer扩展 #
词法分析扩展是相当直接的. 首先我们为新的tokens增加新的enum值.
// control
tok_if = -6,
tok_then = -7,
tok_else = -8,
一旦我们有了它们 我们就意识到了在词法分析器中有了新的keywords(关键字). This is pretty simple stuff:
...
if (IdentifierStr == "def")
return tok_def;
if (IdentifierStr == "extern")
return tok_extern;
if (IdentifierStr == "if")
return tok_if;
if (IdentifierStr == "then")
return tok_then;
if (IdentifierStr == "else")
return tok_else;
return tok_identifier;
if/then/else的AST 扩展 #
if/then/else 属于表达式, 所以==IfExprAST==继承自==ExprAST==.
/// IfExprAST - Expression class for if/then/else.
class IfExprAST : public ExprAST {
std::unique_ptr<ExprAST> Cond, Then, Else;
public:
IfExprAST(std::unique_ptr<ExprAST> Cond, std::unique_ptr<ExprAST> Then,
std::unique_ptr<ExprAST> Else)
: Cond(std::move(Cond)), Then(std::move(Then)), Else(std::move(Else)) {}
Value *codegen() override;
};
if/then/else的parser扩展 #
现在我们有了词法分析的tokens和AST节点, 我们现在的解析逻辑就相当直接了.
首先我们定义一个新的解析函数:
/// ifexpr ::= 'if' expression 'then' expression 'else' expression
static std::unique_ptr<ExprAST> ParseIfExpr() {
getNextToken(); // eat the if.
// condition.
auto Cond = ParseExpression();
if (!Cond)
return nullptr;
if (CurTok != tok_then)
return LogError("expected then");
getNextToken(); // eat the then
auto Then = ParseExpression();
if (!Then)
return nullptr;
if (CurTok != tok_else)
return LogError("expected else");
getNextToken();
auto Else = ParseExpression();
if (!Else)
return nullptr;
return llvm::make_unique<IfExprAST>(std::move(Cond), std::move(Then),
std::move(Else));
}
现在我们将它与primay expression连接起来:
static std::unique_ptr<ExprAST> ParsePrimary() {
switch (CurTok) {
default:
return LogError("unknown token when expecting an expression");
case tok_identifier:
return ParseIdentifierExpr();
case tok_number:
return ParseNumberExpr();
case '(':
return ParseParenExpr();
case tok_if:
return ParseIfExpr();
}
}
if/then/else的LLVM IR #
现在我们已经解析完成并且建立了抽象语法树, 最后的内容是增加==LLVM code generation support==. 这是 if/else/then的例子中最有趣的地方, 因为它开始引入了新的概念. 上面所有的代码都在以前的章节详细介绍过.
为了产生我们想要得到的代码. 让我们看一个简单的例子. Consider:
extern foo();
extern bar();
def baz(x) if x then foo() else bar();
如果禁用优化, 你可以看到生成的IR是下面这样的:
declare double @foo()
declare double @bar()
define double @baz(double %x) {
entry:
%ifcond = fcmp one double %x, 0.000000e+00
br i1 %ifcond, label %then, label %else
then: ; preds = %entry
%calltmp = call double @foo()
br label %ifcont
else: ; preds = %entry
%calltmp1 = call double @bar()
br label %ifcont
ifcont: ; preds = %else, %then
%iftmp = phi double [ %calltmp, %then ], [ %calltmp1, %else ] ; 返回值
ret double %iftmp
}
为了使流程图可视化:
-
你能够使用LLVM opt tool的一个漂亮的功能. 如果你将LLVM IR放到 “t.ll"中, 并且运行
llvm-as < t.ll | opt -analyze -view-cfg, 一个window将会弹出, 并且你将会看到这幅图: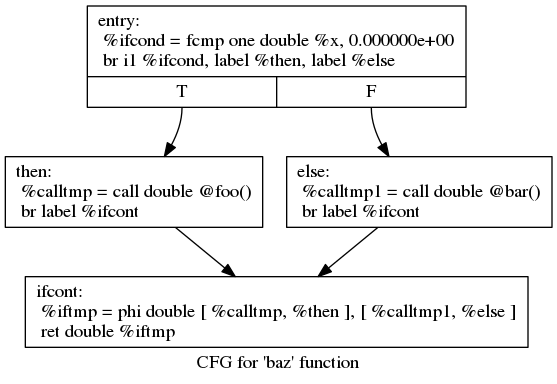
-
另一种方法: 可以通过调用
F->viewCFG()或者F->viewCFGOnly()(where F is a “Function”)通过插入实际的调用到代码中并且重新编译, 可以得到我们想要的CFG图. 或者通过在编译器中调用他们. LLVM具有许多很友好的特性来可视化出各种各样的图形.
回到我们的Codegen代码中, 它是相当简单地:
The entry block: 计算条件表达式 (在我们的例子中是"x” ) 并且使用==fcmp one==指令将result与0.0相比较 ( one 表示有序并且不相等). 基于该表达式的结果, 代码跳转到then block 或者 else block, which 包含 true/false cases的表达式.
一旦 then/else block执行完成了, 他们都返回到**“ifcont” block**来执行 if/then/else 之后发生的代码. 在这种情况下, 唯一要做的事情就是返回到函数的调用者.
现在我们的问题是: 代码是如何知道哪一个表达式要返回的呢?
这个问题的答案涉及重要的SSA 操作: the Phi operation(或者看我之前翻译的文章: Staitc Single Assignment). 如果你不熟悉SSA, the wikipedia article是一个很不错的入门并且你最喜欢的搜索引擎上各种其它的介绍.
一个简单的对$phi$ 函数执行的介绍是: 可以确定我们是从哪一个表达式返回的. The phi operation采用与输入控制块相对应的value.
在这个例子中, 如果控制来自 “then” block, 则它获得calltmp的值.
如果控制来自**“else” block**, 它获得calltmp1的值.
此刻, 你可能已经开始思考了. “Oh no!” 这意味着我的简单优雅的前端必须开始生成SSA 才能使用LLVM. 幸运地是, 我们强烈建议不要在你的前端实现SSA构造算法除非你有一个非常好的理由这样做. 实际上, 对于你的命令行式编程语言来说,出现下面这两种情况时, 这表明此刻可能需要Phi nodes:
- 代码涉及用户变量: x = 1; x = x + 1;
- Values可能隐式地在AST结构中, 例如在本例子中的Phi node.
在 第七章 (“多元变量”), 我们将讨论第一种情况. 现在, 请相信我你不需要SSA构造来处理这种情况.
对于第二种情况, 你可以选择使用我们将为 #1描述的技术. 或者你能直接插入Phi 节点(如果方便的话).
在我们这个例子中 产生 Phi code真的是简单的, 所以我们选择直接插入Phi节点.
Okay. 我们已经了解了足够多, 让我们生成代码吧.
if/then/else 的代码产生 #
为了产生代码, 我们需要实现IfExpAST的codegen方法.
Value *IfExprAST::codegen() {
Value *CondV = Cond->codegen();
if (!CondV)
return nullptr;
// Convert condition to a bool by comparing non-equal to 0.0.
// 转换条件到一个bool值.
CondV = Builder.CreateFCmpONE(
CondV, ConstantFP::get(TheContext, APFloat(0.0)), "ifcond");
这段代码很直接, 和我们之前看到的类似. 我们 emit the expression for the condition, 然后将值与0进行比较, 得到bool值.
Function *TheFunction = Builder.GetInsertBlock()->getParent();
// Create blocks for the then and else cases. Insert the 'then' block at the
// end of the function.
// 创建then and else case的blocks.
// 插入 'then' block在函数的最后
BasicBlock *ThenBB =
BasicBlock::Create(TheContext, "then", TheFunction);
BasicBlock *ElseBB = BasicBlock::Create(TheContext, "else");
BasicBlock *MergeBB = BasicBlock::Create(TheContext, "ifcont");
Builder.CreateCondBr(CondV, ThenBB, ElseBB);
这个代码创建与 if/then/else语句相关的basic block, 并且直接对应于上例中的块.
第一行获取当前正在构建的Function对象: 它通过询问Builder当前的BasicBlock, 并询问当前Block的parent, 来获取此信息.
获得函数之后, 我们会创建三个Blocks. 注意: 它传递"TheFunction到"then"block的构造器中. 这会导致构造函数会自动地在指定的函数中插入new block. 其他的两个block被创建, 但是还没有被插入.
一旦block被创建, 我们就可以emit the 在它们之间选择的条件分支. 注意, 创建新的block不会隐式地影响IRBuilder, 因此它仍然可以插入条件到进入的块中. 另外要注意, 它正在创建到"then"block和"else"block的分支, 即使"else"block还未插入到函数中.
This is all ok. 它是LLVM支持==forward references==的标准方法.
// Emit then value.
Builder.SetInsertPoint(ThenBB);
Value *ThenV = Then->codegen();
if (!ThenV)
return nullptr;
Builder.CreateBr(MergeBB);
// Codegen of 'Then' can change the current block, update ThenBB for the PHI.
// 'Then'的Codegen会改变目前的block, update ThenBB for the PHI.
ThenBB = Builder.GetInsertBlock();
在条件分支被插入之后, 我们move the builder来插入"then"block. 严格上来说, this call移动插入点到指定block的end. 然而, 由于 “then” block是空的, 所以它就会从block的开始进行插入.
一旦插入点被设置了, 我们可以递归地从AST中codegen the “then"表达式. 为了完成"then"块, 我们为合并块创建了一个无条件分支.
LLVM IR一个有趣的方面是它要求所有的BasicBlock都用控制流指令来中止(Ex: return and branch).
这意味着所有的控制流, including fall throughs, 必须在LLVM IR中被显示地指定. 如果违反此规则, 验证程序会报错.
这里的最后一行相当微妙, 但是是非常重要的. 基本问题就是当我们在merge block中创建 Phi node时, 我们需要设置 block/value pairs 来表明Phi是如何工作的. 重要的 , The Phi node 期待在CFG的块中每一个前节点都有一个entry.
那么, 为什么在第 5 行, 我们设置ThenBB为获取当前块呢? “Then"表达式实际上可能会改变当前的block. 例如, 它包含了一个嵌套的"if/then/else"表达式. 因为递归地调用codegen()会任意改变当前块的notion, 我们需要得到将要设置的Phi node代码的最新值.
// Emit else block.
TheFunction->getBasicBlockList().push_back(ElseBB);
Builder.SetInsertPoint(ElseBB);
Value *ElseV = Else->codegen();
if (!ElseV)
return nullptr;
Builder.CreateBr(MergeBB);
// codegen of 'Else' can change the current block, update ElseBB for the PHI.
ElseBB = Builder.GetInsertBlock();
’else’代码块的codegen与’then’ block的codegen基本相同. 唯一的显著差异是第一行: 它将"else"block 添加到函数中. 回想之前, 我们已经创建了’else’块, 但未添加到该函数中.
现在then 和 else 代码块的IR都已经产生了, 我们现在可以完成我们的Merge代码了.
// Emit merge block.
TheFunction->getBasicBlockList().push_back(MergeBB);
Builder.SetInsertPoint(MergeBB);
PHINode *PN =
Builder.CreatePHI(Type::getDoubleTy(TheContext), 2, "iftmp");
PN->addIncoming(ThenV, ThenBB);
PN->addIncoming(ElseV, ElseBB);
return PN;
}
开始的两行是相似的: 第一行添加 “merge” block到function object中(之前merge block被创建之后, 还没有插入函数中). 第二行改变插入点位置, 所以新的codegen的代码会在Merge Block中. 一旦做完这些之后, 我们需要创建PHI node并且给phi 节点设置一组值(block/value pairs).
最后, CodeGen函数返回 phi nodes作为if/then/else表达式计算的值. 在我们上面的例子中, 返回值将会提供给顶级函数的代码中, 该函数将会创建返回指令.
总的来说, 我们现在能够在Kaleidoscope中执行条件代码. 加入这项扩展之后, Kaleidoscope是一个相当完整的语言(因为它可以计算大量的数值函数).
下一步我们将会添加另一个有用的表达式 that is familiar from non-functional languages.
‘for’ Loop Expression #
现在我们知道了如何在语言中添加基本的控制流, 我们有了一些工具来添加更多强大的功能.
让我们来做一些更有趣的, ‘for’ expression:
extern putchard(char);
def printstar(n)
for i = 1, i < n, 1.0 in
putchard(42); # ascii 42 = '*'
# print 100 '*' characters
printstar(100);
在此例中, 这个表达式定义的一个新的变量(“i”), i 从初始值开始迭代, 当条件( “i < n” )为true时, 以步长(“1.0”)开始增加.
如果步长被省略了, 默认设置它为1.0.
当循环条件为true时, 它会执行它的body expression. 因为我们没有什么要返回的, 所以我们定义the loop总是返回0.0.
在未来当我们有可变变量时, 它会变得更有用.
像往常一样, 让我们开始讨论如何设计Kaleidoscope来支持 for循环.
Lexer Extensions for the ‘for’ Loop #
扩展词法分析器与 if/then/else相似:
... in enum Token ...
// control
tok_if = -6, tok_then = -7, tok_else = -8,
tok_for = -9, tok_in = -10
... in gettok ...
if (IdentifierStr == "def")
return tok_def;
if (IdentifierStr == "extern")
return tok_extern;
if (IdentifierStr == "if")
return tok_if;
if (IdentifierStr == "then")
return tok_then;
if (IdentifierStr == "else")
return tok_else;
if (IdentifierStr == "for")
return tok_for;
if (IdentifierStr == "in")
return tok_in;
return tok_identifier;
AST Extensions for the ‘for’ Loop #
The AST node也很简单. 它基本上就是包含: 节点中的变量名 和 组成它的表达式.
/// ForExprAST - Expression class for for/in.
class ForExprAST : public ExprAST {
std::string VarName; // 迭代器变量名称
std::unique_ptr<ExprAST> Start, End, Step, Body;
public:
ForExprAST(const std::string &VarName, std::unique_ptr<ExprAST> Start,
std::unique_ptr<ExprAST> End, std::unique_ptr<ExprAST> Step,
std::unique_ptr<ExprAST> Body)
: VarName(VarName), Start(std::move(Start)), End(std::move(End)),
Step(std::move(Step)), Body(std::move(Body)) {}
Value *codegen() override;
};
Parser Extensions for the ‘for’ Loop #
解析器代码也是相当标准的.
唯一有趣的事情是这里会处理可选的步长. 解析器代码通过检查第二个逗号是否存在来处理. 如果没有发现逗号, 我们会在AST节点中将步长设置为null.
/// forexpr ::= 'for' identifier '=' expr ',' expr (',' expr)? 'in' expression
static std::unique_ptr<ExprAST> ParseForExpr() {
getNextToken(); // eat the for.
if (CurTok != tok_identifier)
return LogError("expected identifier after for");
std::string IdName = IdentifierStr;
getNextToken(); // eat identifier.
if (CurTok != '=')
return LogError("expected '=' after for");
getNextToken(); // eat '='.
auto Start = ParseExpression();
if (!Start)
return nullptr;
if (CurTok != ',')
return LogError("expected ',' after for start value");
getNextToken();
auto End = ParseExpression();
if (!End)
return nullptr;
// The step value is optional.
std::unique_ptr<ExprAST> Step;
if (CurTok == ',') {
getNextToken();
Step = ParseExpression();
if (!Step)
return nullptr;
}
if (CurTok != tok_in)
return LogError("expected 'in' after for");
getNextToken(); // eat 'in'.
auto Body = ParseExpression();
if (!Body)
return nullptr;
return llvm::make_unique<ForExprAST>(IdName, std::move(Start),
std::move(End), std::move(Step),
std::move(Body));
}
当然了, 我们会将它作为主表达式的一部分.
static std::unique_ptr<ExprAST> ParsePrimary() {
switch (CurTok) {
default:
return LogError("unknown token when expecting an expression");
case tok_identifier:
return ParseIdentifierExpr();
case tok_number:
return ParseNumberExpr();
case '(':
return ParseParenExpr();
case tok_if:
return ParseIfExpr();
case tok_for:
return ParseForExpr();
}
}
LLVM IR for the ‘for’ loop #
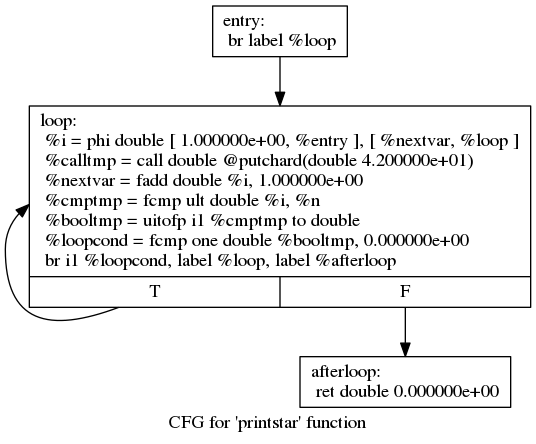
下一步, 我们现在需要为For循环产生IR. 根据上面的例子, 我们可以产生下面这样的IR(注意: 为了清楚起见, 我们在产生时关闭了优化):
declare double @putchard(double)
define double @printstar(double %n) {
entry:
; initial value = 1.0 (inlined into phi)
br label %loop
loop: ; preds = %loop, %entry
%i = phi double [ 1.000000e+00, %entry ], [ %nextvar, %loop ]
; body
%calltmp = call double @putchard(double 4.200000e+01)
; increment
%nextvar = fadd double %i, 1.000000e+00
; termination test
%cmptmp = fcmp ult double %i, %n
%booltmp = uitofp i1 %cmptmp to double
%loopcond = fcmp one double %booltmp, 0.000000e+00
br i1 %loopcond, label %loop, label %afterloop
afterloop: ; preds = %loop
; loop always returns 0.0
ret double 0.000000e+00
}
该循环包含我们之前看到的相同的结构: a phi node, several expressions, and some basic blocks.
CFG:
Code Generation for the ‘for’ Loop #
codegen的第一部分是简单的, 我们只是输出循环的起始表达式:
Value *ForExprAST::codegen() {
// Emit the start code first, without 'variable' in scope.
Value *StartVal = Start->codegen();
if (!StartVal)
return nullptr;
在此之后, 下一步是为loop body的启动设置LLVM basic block. 在上面的例子中, 整个loop body是一个block. 但是记住: body node 本身可以包含多个blocks. (E.g: 它可以包含 if/then/else 或者 a for/in expression).
// Make the new basic block for the loop header, inserting after current
// block.
// 为loop header make新的basic block, 在当前block之后插入
Function *TheFunction = Builder.GetInsertBlock()->getParent();
BasicBlock *PreheaderBB = Builder.GetInsertBlock();
BasicBlock *LoopBB =
BasicBlock::Create(TheContext, "loop", TheFunction);
// Insert an explicit fall through from the current block to the LoopBB.
// 从当前块插入explicit fall through to the LoopBB
Builder.CreateBr(LoopBB);
代码与我们在if/then/else中看到的代码相似. 因为之后我们将会需要它来创建一个Phi node, 所以我们保存了那个刚进入循环的块.
在做完这些之后, 我们创建Loop Block, 并且为两个块之前的连接创建一个无条件分支.
// Start insertion in LoopBB. 开始插入
Builder.SetInsertPoint(LoopBB);
// Start the PHI node with an entry for Start.
PHINode *Variable = Builder.CreatePHI(Type::getDoubleTy(TheContext),
2, VarName.c_str());
Variable->addIncoming(StartVal, PreheaderBB);
现在 loop 的**“preheader”**已经设置好了, 我们切换到为 loop body来emitting code.
首先: 我们移动插入点, and 为loop indunction 变量创建PHI node. 由于我们已经知道起始值的传入值, 我们将它加入到PHI node 中.
注意到Phi之后会最终获得备份的第二个值, 但是我们现在还不能set it up yet (因为它目前还不存在!)
// Within the loop, the variable is defined equal to the PHI node. If it
// shadows an existing variable, we have to restore it, so save it now.
Value *OldVal = NamedValues[VarName];
NamedValues[VarName] = Variable;
// Emit the body of the loop. This, like any other expr, can change the
// current BB. Note that we ignore the value computed by the body, but don't
// allow an error.
if (!Body->codegen())
return nullptr;
现在代码开始变得有趣了, 我在符号表中为for 循环引入了新的变量. 这意味着: 我们的符号表现在可以包含函数参数 或者循环变量. 为了处理这个问题, 在我们为循环体body 进行 codegen之前, 我们在符号表中添加该循环变量的名称以及它的当前值.
注意: 外部作用域可能会有相同的变量名称. 我们很容易会犯这个错误(就是如果已经存在varName, 我们会采取报错并且返回error这个措施). 但是我们选择了允许隐藏存在的变量. 为了正确的实现该目标, 我们会保存之前存在的varName的值(当然了, 如果之前没有varName的话, 我们会设置它为null).
一旦将循环变量加入到符号表中之后, 我们就可以递归地对Body进行Codegen. 我们允许body使用循环变量: 我们可以在符号表中找到循环变量, 来实现对它的引用.
// Emit the step value.
Value *StepVal = nullptr;
if (Step) {
StepVal = Step->codegen();
if (!StepVal)
return nullptr;
} else {
// If not specified, use 1.0.
StepVal = ConstantFP::get(TheContext, APFloat(1.0));
}
Value *NextVar = Builder.CreateFAdd(Variable, StepVal, "nextvar");
现在 the body is emitted, 我们计算迭代器的下一个值. (迭代器的下一个值= 迭代器当前的值+步长; 如果步长未被设置, 默认为 1.0)
‘NextValue‘将会是循环的下一次迭代的迭代器值.
// Compute the end condition.
Value *EndCond = End->codegen();
if (!EndCond)
return nullptr;
// Convert condition to a bool by comparing non-equal to 0.0.
EndCond = Builder.CreateFCmpONE(
EndCond, ConstantFP::get(TheContext, APFloat(0.0)), "loopcond");
最后, 我们计算循环的退出值, 来决定是否退出循环. 这与 if/then/else 语句的条件值计算是一样的.
// Create the "after loop" block and insert it.
BasicBlock *LoopEndBB = Builder.GetInsertBlock();
BasicBlock *AfterBB =
BasicBlock::Create(TheContext, "afterloop", TheFunction);
// Insert the conditional branch into the end of LoopEndBB.
Builder.CreateCondBr(EndCond, LoopBB, AfterBB);
// Any new code will be inserted in AfterBB.
Builder.SetInsertPoint(AfterBB);
随着循环体的代码完成, 我们现在只需要为它完成控制流程. 该代码保存end block(for the phi node), 然后为Loop exit(“afterloop”)创建 block. 基于退出条件的值, 它创建了一个条件分支来来在再一次执行循环和退出循环之前选择. 任何之后创建的指令都会在 afterloop block 中, 所以我们设置了Builder的插入位置.
// Add a new entry to the PHI node for the backedge.
Variable->addIncoming(NextVar, LoopEndBB);
// Restore the unshadowed variable.
if (OldVal)
NamedValues[VarName] = OldVal;
else
NamedValues.erase(VarName);
// for expr always returns 0.0.
return Constant::getNullValue(Type::getDoubleTy(TheContext));
}
最后的代码处理各种cleanups: 现在我们有了 “NextVar” 值, 我们可以将NextVar/LoopEndBB添加到 Loop PHI node中. 在这之后, 我们从符号表中移除循环变量. 所以 for 循环完成之后, 它就不在作用域中了. 最后, for 循环的代码产生总是返回 0.0, 这就是我们从 ForExprAST::codegen()中返回的内容.
现在我们总结本教程中 “adding control flow to Kaleidoscope” 这章.
在本章, 我们增加了两个控制流结构, 通过实现我们了解到了 LLVM IR 的几个方面 (这些对于编译器前端实现者来说是很重要的).
在下一章, 我们将会变得更疯狂并且我们会为我们的Kaleidoscope添加用户自定义的运算符.