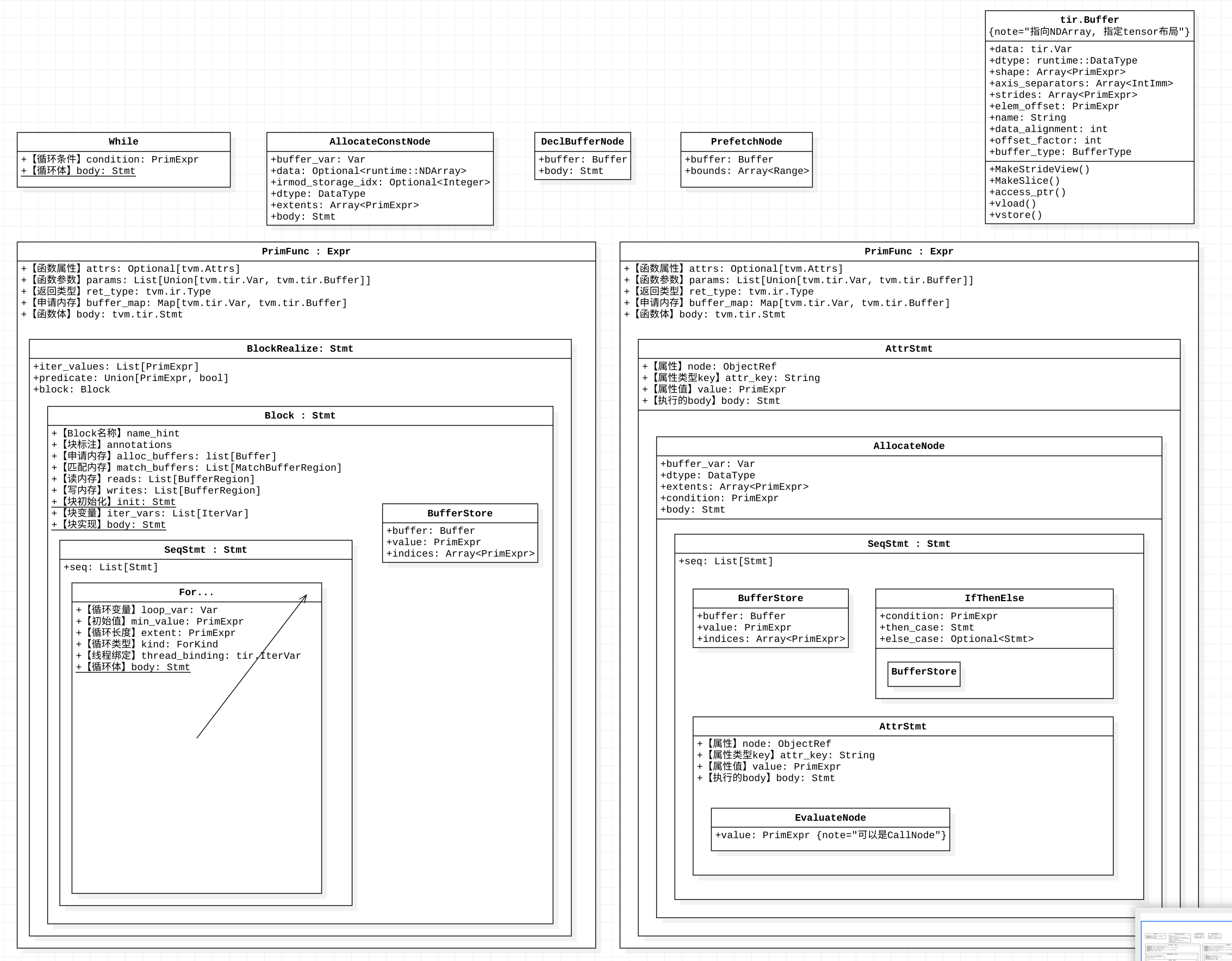
下面是TIR的AST结构:
TIR Schedule #
解析mod信息:
- 获取block:sch.get_block
- 获取loops:sch.get_loops
线程相关:
- (线程绑定)sch.bind:sch.bind(bx, “blockIdx.x”)、sch.bind(tx, “threadIdx.x”) 循环相关:
- (循环拆分)sch.split
- (循环重排)sch.reorder
- (循环展开标注)sch.annotate(tx, ann_key=“pragma_auto_unroll_max_step”/“pragma_unroll_explicit”)
- (向量化)sch.vectorize
- (合并)sch.fuse 块相关:
- sch.reindex
- sch.cache_read, sch.cache_write 存储相关:
- sch.transform_layout
Thread #
- 线程分配和运行:
- 高级原语:thread_binding
- 低级原语:allocate、launch_thread
allocate 和 launch_thread(T.thread_binding) #
thread reduce #
提供API #
NormalizePrimFunc #
# src/tir/schedule/transform.cc
TVM_REGISTER_GLOBAL("tir.schedule.NormalizePrimFunc").set_body_typed(NormalizePrimFunc);
函数流程:
- check
- 构造index_map_inputs和index_map_outputs
- 根据map对block的layer进行变换
- 判断block是否是reduction block
Optional<ObjectRef> NormalizePrimFunc(Schedule sch) {
BlockRV root_block = sch->GetBlock("root");
Array<BlockRV> blocks = sch->GetChildBlocks(root_block);
# 1. check
for (const BlockRV& block : blocks) {
StmtSRef block_sref = sch->GetSRef(block);
Array<StmtSRef> loops = GetLoops(block_sref);
Array<PrimExpr> binds = GetBlockRealize(sch->state(), block_sref)->iter_values;
if (loops.size() != binds.size()) {
return NullOpt;
}
for (int i = 0, n = loops.size(); i < n; ++i) {
const ForNode* loop = TVM_SREF_TO_FOR(loops[i]);
if (binds[i].get() != loop->loop_var.get()) {
return NullOpt;
}
if (!is_zero(loop->min)) {
return NullOpt;
}
}
}
Array<Array<LoopRV>> block_loops;
Array<Array<IterVar>> block_iters;
Array<IntImm> block_is_reduction;
#
for (const BlockRV& block : blocks) {
Array<IterVar> iters = sch->Get(block)->iter_vars;
bool has_spatial_iter = false;
# 2. 构造index_map_inputs和index_map_outputs
Array<Var> index_map_inputs;
Array<PrimExpr> index_map_outputs;
for (const IterVar& iter : sch->Get(block)->iter_vars) {
Var var = iter->var.copy_with_suffix("");
index_map_inputs.push_back(var);
if (!is_one(iter->dom->extent)) {
index_map_outputs.push_back(var);
if (iter->iter_type == IterVarType::kDataPar) {
has_spatial_iter = true;
}
}
}
if (index_map_outputs.empty() || !has_spatial_iter) {
index_map_outputs.insert(index_map_outputs.begin(), tir::make_const(DataType::Int(64), 0));
}
# 3. 根据map对block的layer进行变换
sch->TransformBlockLayout(block, IndexMap(index_map_inputs, index_map_outputs));
block_loops.push_back(sch->GetLoops(block));
block_iters.push_back(sch->Get(block)->iter_vars);
# 4. 判断block是否是reduction block
bool is_reduction = IsReductionBlock(sch->state(), //
sch->GetSRef(block), //
sch->GetSRef(root_block));
block_is_reduction.push_back(Bool(is_reduction));
}
return Array<ObjectRef>{blocks, block_loops, block_iters, block_is_reduction};
}
is_reduction #
针对是否reduction函数的判断:
- 收集所有的reduction轴;
- 收集所有的write buffer;
- 收集所有的alloc buffer;
DLight #
Matmul #
源码路径:python/tvm/dlight/gpu/matmul.py sch流程:
- 检查tensor core支持
- 获取schedule config
- do schedule
GEMV #
案例展示:
E = relax.Var("A", R.Tensor([10, 20, 1, 1], "int64"))
F = relax.Var("B", R.Tensor([10, 20, 1, 30], "int64"))
with bb.function("matmul_5"):
with bb.dataflow():
lv0 = relax.op.matmul(E, F)
gv = bb.emit_output(lv0)
bb.emit_func_output(gv, [E, F])
>>>
实现:
- Norm Block,得到block_info
def apply( # pylint: disable=too-many-locals,too-many-branches,too-many-return-statements
self,
func: tir.PrimFunc,
target: Target,
_: bool,
) -> Union[None, tir.Schedule, List[tir.Schedule]]:
sch = tir.Schedule(func)
block_infos = normalize_prim_func(sch)
block_infos = try_inline_contiguous_spatial(sch, block_infos)
if len(block_infos) == 1:
epilogue = None
elif len(block_infos) == 2:
epilogue = block_infos[1]
if not epilogue.is_injective():
return None
else:
return None
block_info = block_infos[0]
if len(block_info.iters) not in [2, 3]:
# either [B, S, R] = [B, S, R] * [B, R]
# or [S, R] = [S, R] * [R]
return None
block = block_info.block_rv
vector_input_buffers = is_gemv(sch, block_info)
if vector_input_buffers is None:
return None
# Step 1. Normalize the block, merge spatial and reduction iters
is_inner_reduction = normalize(sch, block_info)
# Step 2. Do the scheduling
if is_inner_reduction:
self.sch_inner_reduction(sch, target, block, vector_input_buffers, epilogue)
return sch
else:
# TODO: Need to handle GEMV with KN layout
return None
normalize #
sch_inner_reduction #
Reduction #
案例展示:tir_script:包含3个spatial轴,一个reduce轴
@T.prim_func(private=True)
def main(
A: T.Buffer((T.int64(10), T.int64(20), T.int64(1)), "int64"),
B: T.Buffer((T.int64(10), T.int64(1), T.int64(30)), "int64"),
matmul: T.Buffer((T.int64(10), T.int64(20), T.int64(30)), "int64"),
):
T.func_attr({"op_pattern": 4, "tir.noalias": T.bool(True)})
# with T.block("root"):
for i0, i1, i2, k in T.grid(T.int64(10), T.int64(20), T.int64(30), T.int64(1)):
with T.block("matmul"):
v_i0, v_i1, v_i2, v_k = T.axis.remap("SSSR", [i0, i1, i2, k])
T.reads(A[v_i0, v_i1, v_k], B[v_i0, v_k, v_i2])
T.writes(matmul[v_i0, v_i1, v_i2])
with T.init():
matmul[v_i0, v_i1, v_i2] = T.int64(0)
matmul[v_i0, v_i1, v_i2] = (
matmul[v_i0, v_i1, v_i2] + A[v_i0, v_i1, v_k] * B[v_i0, v_k, v_i2]
)
# 1. Norm
>>> block_infos = dl.base.analysis.normalize_prim_func(sch)
[BlockInfo("matmul", "SSS", [10, 20, 30])] # 只有三个spatial轴
>>> block_info.is_reduction(), block_stmt.writes, dl.gpu.reduction._get_reduction_expr(block_stmt)
T.bool(True) # 注意, 这里为true
[matmul[v0, v1, v2]]
A[v0, v1, T.int64(0)] * B[v0, T.int64(0), v2]
>>> block_stmt = sch.get(block) # 这里没有reduce轴
with T.block("matmul", no_realize=True):
v0 = T.axis.spatial(T.int64(10))
v1 = T.axis.spatial(T.int64(20))
v2 = T.axis.spatial(T.int64(30))
A = T.Buffer((T.int64(10), T.int64(20), T.int64(1)), "int64")
B = T.Buffer((T.int64(10), T.int64(1), T.int64(30)), "int64")
T.reads(A[v0, v1, T.int64(0)], B[v0, T.int64(0), v2])
matmul = T.Buffer((T.int64(10), T.int64(20), T.int64(30)), "int64")
T.writes(matmul[v0, v1, v2])
with T.init():
matmul[v0, v1, v2] = T.int64(0)
matmul[v0, v1, v2] = matmul[v0, v1, v2] + A[v0, v1, T.int64(0)] * B[v0, T.int64(0), v2]
>>> dl.base.analysis.detect_dominant_read(block_stmt)
v0 * T.int64(20) + v1
>>> access # 读取的轴:v0, v1
IterSum([
IterSplit(IterMark(v0, extent=T.int64(10)), lower_factor=T.int64(1), extent=T.int64(10), scale=T.int64(20)), IterSplit(IterMark(v1, extent=T.int64(20)), lower_factor=T.int64(1), extent=T.int64(20), scale=T.int64(1))], T.int64(0))
schedule流程:
- 对func进行norm,得到block_infos
- 检查reduction block
- 合并spatial和reduction iters
- do schedule
# 1. 得到block_infos
sch = tir.Schedule(func)
block_infos = normalize_prim_func(sch)
# 2. check
if (
(not block_info.is_reduction())
or len(block_stmt.writes) != 1
or _get_reduction_expr(block_stmt) is None
):
return None
# 3. 合并spatial和reduction iters
is_inner_reduction, c_factor = self._normalize(
sch,
block_info,
arith.normalize_to_iter_sum(
detect_dominant_read(block_stmt),
input_iters={i.var: i.dom for i in block_stmt.iter_vars},
),
)
# 4. 执行schedule
if is_inner_reduction:
self._sch_inner_reduction(sch, target, block, c_factor, epilogue)
else:
self._sch_inner_spatial(sch, target, block, c_factor, epilogue)
_normalize #
schedule #
函数签名:
- 参数:mod的sch, target,
- 返回:sch
def _sch_inner_spatial(
self,
sch: tir.Schedule,
target: Target,
block: tir.schedule.BlockRV,
unroll_spatial_factor: Optional[int],
epilogue_info: Optional[BlockInfo],
):
_sch_inner_reduction #
_sch_inner_spatial #
Tranpose #
build #
Reduction #
- 循环展开,warp/block外add
- 二次warpReduce
- warp内shfl,计算结果存储到shared memory中
- 一组thread继续shfl,得到计算结果
lower to tir mod 降级之后的tir script:
@T.prim_func
def main(
A: T.Buffer((T.int64(2048), T.int64(8192)), "float32"),
A_red: T.Buffer((T.int64(2048),), "float32"),
):
T.func_attr(
{"op_pattern": 3, "tir.is_scheduled": 1, "tir.noalias": T.bool(True)}
)
blockIdx_x = T.launch_thread("blockIdx.x", 2048) # blockIdx
A_red_rf_local = T.allocate([1], "float32", "local")
cross_thread_A_red = T.allocate([1], "float32", "local")
threadIdx_x = T.launch_thread("threadIdx.x", 256) # threadIdx
A_red_rf_local_1 = T.Buffer((T.int64(1),), data=A_red_rf_local, scope="local")
A_red_rf_local_1[0] = T.float32(0)
A_1 = T.Buffer((T.int64(16777216),), data=A.data) # 引用参数数据
# 循环展开
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 8192 + threadIdx_x]
A_red_rf_local_1[0] = (
A_red_rf_local_1[0] + A_1[blockIdx_x * 8192 + threadIdx_x + 256]
)
A_red_rf_local_1[0] = (
A_red_rf_local_1[0] + A_1[blockIdx_x * 8192 + threadIdx_x + 512]
)
A_red_rf_local_1[0] = (
A_red_rf_local_1[0] + A_1[blockIdx_x * 8192 + threadIdx_x + 768]
)
A_red_rf_local_1[0] = (
A_red_rf_local_1[0] + A_1[blockIdx_x * 8192 + threadIdx_x + 1024]
)
...
cross_thread_A_red_1 = T.Buffer((1,), data=cross_thread_A_red, scope="local")
# 256个线程reduce
with T.attr(
T.comm_reducer(lambda x0, y0: x0 + y0, [T.float32(0)]),
"reduce_scope",
T.reinterpret("handle", T.uint64(0)),
):
T.tvm_thread_allreduce(
T.uint32(1),
A_red_rf_local_1[0],
T.bool(True),
cross_thread_A_red_1[0],
threadIdx_x,
)
# 写回返回参数中
if threadIdx_x == 0:
A_red_1 = T.Buffer((T.int64(2048),), data=A_red.data)
A_red_1[blockIdx_x] = cross_thread_A_red_1[0]
【tvm.build->tir_to_runtime】mix mod lower之后:
- 包含main_kernel和main 元函数
@I.ir_module
class Module:
I.module_attrs({"runtime": None})
@T.prim_func
def main_kernel(A: T.handle("float32", "global"), A_red: T.handle("float32", "global")):
T.func_attr({"calling_conv": 2, "target": T.target({"arch": "sm_75", "keys": ["cuda", "gpu"], "kind": "cuda", "max_num_threads": 1024, "max_shared_memory_per_block": 49152, "max_threads_per_block": 1024, "registers_per_block": 65536, "tag": "", "thread_warp_size": 32}), "tir.is_global_func": T.bool(True), "tir.kernel_launch_params": ["blockIdx.x", "threadIdx.x"], "tir.noalias": T.bool(True)})
blockIdx_x = T.launch_thread("blockIdx.x", 2048)
A_red_rf_local = T.allocate([1], "float32", "local")
red_result = T.allocate([1], "float32", "shared")
T.attr(red_result, "volatile_scope", 1)
threadIdx_x = T.launch_thread("threadIdx.x", 256)
A_red_rf_local_1 = T.Buffer((1,), data=A_red_rf_local, scope="local")
A_red_rf_local_1[0] = T.float32(0)
A_1 = T.Buffer((T.int64(4194304),), data=A)
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 256]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 512]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 768]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 1024]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 1280]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 1536]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 1792]
red_result_1 = T.Buffer((1,), data=red_result, scope="shared")
with T.attr(T.comm_reducer(lambda x0, y0: x0 + y0, [T.float32(0)]), "reduce_scope", T.reinterpret("handle", T.uint64(0))):
red_buf0 = T.allocate([1], "float32", "local")
mask = T.allocate([1], "uint32", "local")
t0 = T.allocate([1], "float32", "local")
red_buf0_1 = T.allocate([1], "float32", "local")
mask_1 = T.allocate([1], "uint32", "local")
t0_1 = T.allocate([1], "float32", "local")
red_buf_staging = T.allocate([8], "float32", "shared")
red_buf0_2 = T.Buffer((1,), data=red_buf0_1, scope="local")
red_buf0_2[0] = A_red_rf_local_1[0]
mask_2 = T.Buffer((1,), "uint32", data=mask_1, scope="local")
mask_2[0] = T.tvm_warp_activemask()
t0_2 = T.Buffer((1,), data=t0_1, scope="local")
t0_2[0] = T.tvm_warp_shuffle_down(mask_2[0], red_buf0_2[0], 16, 32, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tvm_warp_shuffle_down(mask_2[0], red_buf0_2[0], 8, 32, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tvm_warp_shuffle_down(mask_2[0], red_buf0_2[0], 4, 32, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tvm_warp_shuffle_down(mask_2[0], red_buf0_2[0], 2, 32, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tvm_warp_shuffle_down(mask_2[0], red_buf0_2[0], 1, 32, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
red_buf_staging_1 = T.Buffer((8,), data=red_buf_staging, scope="shared")
if threadIdx_x % 32 == 0:
red_buf_staging_1[threadIdx_x // 32] = red_buf0_2[0]
T.tvm_storage_sync("shared")
red_buf0_3 = T.Buffer((1,), data=red_buf0, scope="local")
if threadIdx_x < 8:
red_buf0_3[0] = red_buf_staging_1[threadIdx_x]
mask_3 = T.Buffer((1,), "uint32", data=mask, scope="local")
mask_3[0] = T.bitwise_and(T.tvm_warp_activemask(), T.uint32(255))
t0_3 = T.Buffer((1,), data=t0, scope="local")
t0_3[0] = T.tvm_warp_shuffle_down(mask_3[0], red_buf0_3[0], 4, 32, 32)
red_buf0_3[0] = red_buf0_3[0] + t0_3[0]
t0_3[0] = T.tvm_warp_shuffle_down(mask_3[0], red_buf0_3[0], 2, 32, 32)
red_buf0_3[0] = red_buf0_3[0] + t0_3[0]
t0_3[0] = T.tvm_warp_shuffle_down(mask_3[0], red_buf0_3[0], 1, 32, 32)
red_buf0_3[0] = red_buf0_3[0] + t0_3[0]
if threadIdx_x == 0:
red_result_1[0] = red_buf0_3[0]
T.tvm_storage_sync("shared")
if threadIdx_x == 0:
A_red_1 = T.Buffer((T.int64(2048),), data=A_red)
A_red_1[blockIdx_x] = red_result_1[0]
@T.prim_func
def main(args: T.handle, arg_type_ids: T.handle("int32"), num_args: T.int32, out_ret_value: T.handle("void"), out_ret_tcode: T.handle("int32"), resource_handle: T.handle) -> T.int32:
T.func_attr({"calling_conv": 1, "op_pattern": 3, "target": T.target({"keys": ["cpu"], "kind": "llvm", "tag": ""}), "tir.is_entry_func": T.bool(True), "tir.is_scheduled": 1, "tir.noalias": T.bool(True)})
assert num_args == 2, "main: num_args should be 2"
arg_type_ids_1 = T.decl_buffer((2,), "int32", data=arg_type_ids)
var_A_code: T.int32 = arg_type_ids_1[0]
var_A_red_code: T.int32 = arg_type_ids_1[1]
var_A: T.handle = T.tvm_struct_get(args, 0, 12, "handle")
var_A_red: T.handle = T.tvm_struct_get(args, 1, 12, "handle")
A: T.handle("float32", "global") = T.tvm_struct_get(var_A, 0, 1, "handle")
T.attr(A, "storage_alignment", 64)
main_var_A_shape: T.handle("int64") = T.tvm_struct_get(var_A, 0, 2, "handle")
main_var_A_shape_1 = T.decl_buffer((2,), "int64", data=main_var_A_shape)
main_var_A_strides: T.handle("int64") = T.tvm_struct_get(var_A, 0, 3, "handle")
main_var_A_strides_1 = T.decl_buffer((0,), "int64", data=main_var_A_strides)
dev_id: T.int32 = T.tvm_struct_get(var_A, 0, 9, "int32")
A_red: T.handle("float32", "global") = T.tvm_struct_get(var_A_red, 0, 1, "handle")
T.attr(A_red, "storage_alignment", 64)
main_var_A_red_shape: T.handle("int64") = T.tvm_struct_get(var_A_red, 0, 2, "handle")
main_var_A_red_shape_1 = T.decl_buffer((1,), "int64", data=main_var_A_red_shape)
main_var_A_red_strides: T.handle("int64") = T.tvm_struct_get(var_A_red, 0, 3, "handle")
main_var_A_red_strides_1 = T.decl_buffer((0,), "int64", data=main_var_A_red_strides)
assert var_A_code == 3 or var_A_code == 13 or var_A_code == 7 or var_A_code == 4, "main: Expect arg[0] to be pointer"
assert var_A_red_code == 3 or var_A_red_code == 13 or var_A_red_code == 7 or var_A_red_code == 4, "main: Expect arg[1] to be pointer"
T.attr("default", "device_id", dev_id)
T.attr("default", "device_type", 2)
assert 2 == T.tvm_struct_get(var_A, 0, 4, "int32"), "main.var_A.ndim is expected to equal 2"
assert 2 == T.tvm_struct_get(var_A, 0, 4, "int32"), "main.var_A.ndim is expected to equal 2"
assert T.tvm_struct_get(var_A, 0, 5, "uint8") == T.uint8(2) and T.tvm_struct_get(var_A, 0, 6, "uint8") == T.uint8(32) and T.tvm_struct_get(var_A, 0, 7, "uint16") == T.uint16(1), "main.var_A.dtype is expected to be float32"
assert main_var_A_shape_1[0] == T.int64(2048), "Argument main.var_A.shape[0] has an unsatisfied constraint: T.int64(2048) == main_var_A_shape[0]"
assert main_var_A_shape_1[1] == T.int64(2048), "Argument main.var_A.shape[1] has an unsatisfied constraint: T.int64(2048) == main_var_A_shape[1]"
if not T.isnullptr(main_var_A_strides):
assert T.int64(1) == main_var_A_strides_1[1] and T.int64(2048) == main_var_A_strides_1[0], "main.var_A.strides: expected to be compact array"
T.evaluate(0)
assert T.uint64(0) == T.tvm_struct_get(var_A, 0, 8, "uint64"), "Argument main.var_A.byte_offset has an unsatisfied constraint: T.uint64(0) == T.tvm_struct_get(var_A, 0, 8, \"uint64\")"
assert T.tvm_struct_get(var_A, 0, 10, "int32") == 2, "Argument main.var_A.device_type has an unsatisfied constraint: 2 == T.tvm_struct_get(var_A, 0, 10, \"int32\")"
assert 1 == T.tvm_struct_get(var_A_red, 0, 4, "int32"), "main.var_A_red.ndim is expected to equal 1"
assert 1 == T.tvm_struct_get(var_A_red, 0, 4, "int32"), "main.var_A_red.ndim is expected to equal 1"
assert T.tvm_struct_get(var_A_red, 0, 5, "uint8") == T.uint8(2) and T.tvm_struct_get(var_A_red, 0, 6, "uint8") == T.uint8(32) and T.tvm_struct_get(var_A_red, 0, 7, "uint16") == T.uint16(1), "main.var_A_red.dtype is expected to be float32"
assert main_var_A_red_shape_1[0] == T.int64(2048), "Argument main.var_A_red.shape[0] has an unsatisfied constraint: T.int64(2048) == main_var_A_red_shape[0]"
if not T.isnullptr(main_var_A_red_strides):
assert T.int64(1) == main_var_A_red_strides_1[0], "main.var_A_red.strides: expected to be compact array"
T.evaluate(0)
assert T.uint64(0) == T.tvm_struct_get(var_A_red, 0, 8, "uint64"), "Argument main.var_A_red.byte_offset has an unsatisfied constraint: T.uint64(0) == T.tvm_struct_get(var_A_red, 0, 8, \"uint64\")"
assert T.tvm_struct_get(var_A_red, 0, 10, "int32") == 2, "Argument main.var_A_red.device_type has an unsatisfied constraint: 2 == T.tvm_struct_get(var_A_red, 0, 10, \"int32\")"
assert dev_id == T.tvm_struct_get(var_A_red, 0, 9, "int32"), "Argument main.var_A_red.device_id has an unsatisfied constraint: dev_id == T.tvm_struct_get(var_A_red, 0, 9, \"int32\")"
A_1 = T.decl_buffer((T.int64(2048), T.int64(2048)), data=A)
A_red_1 = T.decl_buffer((T.int64(2048),), data=A_red)
T.call_packed("__tvm_set_device", 2, dev_id)
with T.attr(0, "compute_scope", "main_compute_"):
T.call_packed("main_kernel", A, A_red, 2048, 256)
T.ret(0)
after device mod transform:
- T.tvm_warp_activemask -> T.tir.cuda.__activemask
- T.tvm_warp_shuffle_down –> T.tir.cuda.__shfl_down_sync
- truncmod
@I.ir_module
class Module:
I.module_attrs({"runtime": None})
@T.prim_func
def main_kernel(A: T.handle("float32", "global"), A_red: T.handle("float32", "global")):
T.func_attr({"calling_conv": 2, "target": T.target({"arch": "sm_75", "host": {"keys": ["cpu"], "kind": "llvm", "tag": ""}, "keys": ["cuda", "gpu"], "kind": "cuda", "max_num_threads": 1024, "max_shared_memory_per_block": 49152, "max_threads_per_block": 1024, "registers_per_block": 65536, "tag": "", "thread_warp_size": 32}), "tir.is_global_func": T.bool(True), "tir.kernel_launch_params": ["blockIdx.x", "threadIdx.x"], "tir.noalias": T.bool(True)})
blockIdx_x = T.launch_thread("blockIdx.x", 2048)
A_red_rf_local = T.allocate([1], "float32", "local")
red_result = T.allocate([1], "float32", "shared")
T.attr(red_result, "volatile_scope", 1)
threadIdx_x = T.launch_thread("threadIdx.x", 256)
A_red_rf_local_1 = T.Buffer((1,), data=A_red_rf_local, scope="local")
A_red_rf_local_1[0] = T.float32(0)
A_1 = T.Buffer((T.int64(4194304),), data=A)
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 256]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 512]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 768]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 1024]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 1280]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 1536]
A_red_rf_local_1[0] = A_red_rf_local_1[0] + A_1[blockIdx_x * 2048 + threadIdx_x + 1792]
red_result_1 = T.Buffer((1,), data=red_result, scope="shared")
# attr node
with T.attr(T.comm_reducer(lambda x0, y0: x0 + y0, [T.float32(0)]), "reduce_scope", T.reinterpret("handle", T.uint64(0))):
red_buf0 = T.allocate([1], "float32", "local")
mask = T.allocate([1], "uint32", "local")
t0 = T.allocate([1], "float32", "local")
red_buf0_1 = T.allocate([1], "float32", "local")
mask_1 = T.allocate([1], "uint32", "local")
t0_1 = T.allocate([1], "float32", "local")
red_buf_staging = T.allocate([8], "float32", "shared")
# seq stmt node
# ... BufferStore stmt node
red_buf0_2 = T.Buffer((1,), data=red_buf0_1, scope="local")
red_buf0_2[0] = A_red_rf_local_1[0]
mask_2 = T.Buffer((1,), "uint32", data=mask_1, scope="local")
mask_2[0] = T.tir.cuda.__activemask()
t0_2 = T.Buffer((1,), data=t0_1, scope="local")
t0_2[0] = T.tir.cuda.__shfl_down_sync(mask_2[0], red_buf0_2[0], 16, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tir.cuda.__shfl_down_sync(mask_2[0], red_buf0_2[0], 8, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tir.cuda.__shfl_down_sync(mask_2[0], red_buf0_2[0], 4, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tir.cuda.__shfl_down_sync(mask_2[0], red_buf0_2[0], 2, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tir.cuda.__shfl_down_sync(mask_2[0], red_buf0_2[0], 1, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
# if then else node
red_buf_staging_1 = T.Buffer((8,), data=red_buf_staging, scope="shared")
if T.truncmod(threadIdx_x, 32) == 0:
red_buf_staging_1[T.shift_right(threadIdx_x, 5)] = red_buf0_2[0]
# evaluate node
T.tvm_storage_sync("shared")
# if then else node
red_buf0_3 = T.Buffer((1,), data=red_buf0, scope="local")
if threadIdx_x < 8:
red_buf0_3[0] = red_buf_staging_1[threadIdx_x]
mask_3 = T.Buffer((1,), "uint32", data=mask, scope="local")
mask_3[0] = T.bitwise_and(T.tir.cuda.__activemask(), T.uint32(255))
t0_3 = T.Buffer((1,), data=t0, scope="local")
t0_3[0] = T.tir.cuda.__shfl_down_sync(mask_3[0], red_buf0_3[0], 4, 32)
red_buf0_3[0] = red_buf0_3[0] + t0_3[0]
t0_3[0] = T.tir.cuda.__shfl_down_sync(mask_3[0], red_buf0_3[0], 2, 32)
red_buf0_3[0] = red_buf0_3[0] + t0_3[0]
t0_3[0] = T.tir.cuda.__shfl_down_sync(mask_3[0], red_buf0_3[0], 1, 32)
red_buf0_3[0] = red_buf0_3[0] + t0_3[0]
# if then else node
if threadIdx_x == 0:
red_result_1[0] = red_buf0_3[0]
T.tvm_storage_sync("shared")
if threadIdx_x == 0:
A_red_1 = T.Buffer((T.int64(2048),), data=A_red)
A_red_1[blockIdx_x] = red_result_1[0]
Unroll #
shfl替换warp内add #
lower to tir mod #
lower后的tir script,这是一个stmt.AttrStmt节点:
- node:ObjectRef –> tvm.tir.expr.CommReducer
- attr_key:String
- value:PrimExpr –> tvm.tir.expr.Call
- body: stmt.Evaluate
with T.attr(
T.comm_reducer(lambda x0, y0: x0 + y0, [T.float32(0)]), # node
"reduce_scope", # attr_key
T.reinterpret("handle", T.uint64(0)), # value
): # body
T.tvm_thread_allreduce(
T.uint32(1),
A_red_rf_local_1[0],
T.bool(True),
cross_thread_A_red_1[0],
threadIdx_x,
)
>>> seq_stmt[9].node, type(seq_stmt[9].node)
T.comm_reducer(lambda x0, y0: x0 + y0, [T.float32(0)]),
tvm.tir.expr.CommReducer
>>> seq_stmt[9].attr_key,
'reduce_scope',
>>> seq_stmt[9].value, type(seq_stmt[9].value)
T.reinterpret("handle", T.uint64(0))
tvm.tir.expr.Call
>>> seq_stmt[9].body
...
分析Evaluate节点:
- value:expr.Call
>>> seq_stmt[9].body.value,
T.tvm_thread_allreduce(T.uint32(1), A_red_rf_local_1[0], T.bool(True), cross_thread_A_red_1[0], threadIdx_x),
>>> type(seq_stmt[9].body.value)
tvm.tir.expr.Call
>>> seq_stmt[9].body.value.op # call.op
Op(tir.tvm_thread_allreduce)
lower to mixed transform mod #
在tir to runtime中的split mixed mod中 apply mixed seq passes
- 其中对T.tvm_thread_allreduce的转换->
with T.attr(T.comm_reducer(lambda x0, y0: x0 + y0, [T.float32(0)]), "reduce_scope", T.reinterpret("handle", T.uint64(0))):
red_buf0 = T.allocate([1], "float32", "local")
mask = T.allocate([1], "uint32", "local")
t0 = T.allocate([1], "float32", "local")
red_buf0_1 = T.allocate([1], "float32", "local")
mask_1 = T.allocate([1], "uint32", "local")
t0_1 = T.allocate([1], "float32", "local")
red_buf_staging = T.allocate([8], "float32", "shared")
red_buf0_2 = T.Buffer((1,), data=red_buf0_1, scope="local")
red_buf0_2[0] = A_red_rf_local_1[0]
mask_2 = T.Buffer((1,), "uint32", data=mask_1, scope="local")
mask_2[0] = T.tvm_warp_activemask()
t0_2 = T.Buffer((1,), data=t0_1, scope="local")
# warp shuffle
t0_2[0] = T.tvm_warp_shuffle_down(mask_2[0], red_buf0_2[0], 16, 32, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tvm_warp_shuffle_down(mask_2[0], red_buf0_2[0], 8, 32, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tvm_warp_shuffle_down(mask_2[0], red_buf0_2[0], 4, 32, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tvm_warp_shuffle_down(mask_2[0], red_buf0_2[0], 2, 32, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
t0_2[0] = T.tvm_warp_shuffle_down(mask_2[0], red_buf0_2[0], 1, 32, 32)
red_buf0_2[0] = red_buf0_2[0] + t0_2[0]
# combine warped reduced value
red_buf_staging_1 = T.Buffer((8,), data=red_buf_staging, scope="shared")
if threadIdx_x % 32 == 0:
red_buf_staging_1[threadIdx_x // 32] = red_buf0_2[0]
T.tvm_storage_sync("shared")
red_buf0_3 = T.Buffer((1,), data=red_buf0, scope="local")
if threadIdx_x < 8:
red_buf0_3[0] = red_buf_staging_1[threadIdx_x]
mask_3 = T.Buffer((1,), "uint32", data=mask, scope="local")
mask_3[0] = T.bitwise_and(T.tvm_warp_activemask(), T.uint32(255))
t0_3 = T.Buffer((1,), data=t0, scope="local")
t0_3[0] = T.tvm_warp_shuffle_down(mask_3[0], red_buf0_3[0], 4, 32, 32)
red_buf0_3[0] = red_buf0_3[0] + t0_3[0]
t0_3[0] = T.tvm_warp_shuffle_down(mask_3[0], red_buf0_3[0], 2, 32, 32)
red_buf0_3[0] = red_buf0_3[0] + t0_3[0]
t0_3[0] = T.tvm_warp_shuffle_down(mask_3[0], red_buf0_3[0], 1, 32, 32)
red_buf0_3[0] = red_buf0_3[0] + t0_3[0]
# write to ret
if threadIdx_x == 0:
red_result_1[0] = red_buf0_3[0]
T.tvm_storage_sync("shared")
codegen #
AttrStmtNode #
数据成员:
- node:ObjectRef –> tvm.tir.expr.CommReducer
- attr_key:String
- value:PrimExpr –> tvm.tir.expr.Call
- body: stmt.Evaluate
void CodeGenCUDA::VisitStmt_(const AttrStmtNode* op) {
CodeGenC::VisitStmt_(op);
}
EvaluateNode #
数据成员:
- value:expr.Call
VisitExpr:Call #
函数描述 函数流程:
- 默认开启warp_shuffle
- 根据不同的op类型,执行不同的codegen
- 【TensorCore】tvm_fill_fragment
- 【TensorCore】tvm_load_matrix_sync
- 【TensorCore】tvm_store_matrix_sync
- 【TensorCore】tvm_mma_sync
- 【TensorCore】tvm_bmma_sync
- 【TensorCore】ptx_mma
- 【TensorCore】ptx_mma_sp
- 【TensorCore】ptx_ldmatrix
- 【TensorCore】mma_store
- 【TensorCore】mma_fill
- ptx_cp_async
- ptx_commit_group
- ptx_wait_group
- ptx_ldg32
- 调用CodegenC的visit call
案例分析 #
reduce:mean #
mean实现:
- 求和:sum(axis=-1)
- 除法:divide
@T.prim_func(private=True)
def mean(
A: T.Buffer((T.int64(2048), T.int64(8192)), "float32"),
T_divide: T.Buffer((T.int64(2048),), "float32"),
):
T.func_attr({"op_pattern": 4, "tir.noalias": T.bool(True)})
# with T.block("root"):
A_red = T.alloc_buffer((T.int64(2048),)) # 负责求和, (2048, 8192) -> (2048, )
for ax0, k1 in T.grid(T.int64(2048), T.int64(8192)):
with T.block("A_red"):
v_ax0, v_k1 = T.axis.remap("SR", [ax0, k1])
T.reads(A[v_ax0, v_k1])
T.writes(A_red[v_ax0])
with T.init():
A_red[v_ax0] = T.float32(0)
A_red[v_ax0] = A_red[v_ax0] + A[v_ax0, v_k1]
for ax0 in range(T.int64(2048)): # 负责求均值, (2048,) -> (2048,)
with T.block("T_divide"):
v_ax0 = T.axis.spatial(T.int64(2048), ax0)
T.reads(A_red[v_ax0])
T.writes(T_divide[v_ax0])
T_divide[v_ax0] = A_red[v_ax0] * T.float32(0.0001220703125)
dlight schedule后:
- blockIdx绑定到weight的第一个维度
- 【build之后为循环展开+直接sum】threadIdx限制为256,每个reduce轴计算得到256元素,用于处理reduce轴, 每个线程处理32个元素,包含一个for循环
- 指定unroll标记参数:“pragma_unroll_explicit”: 1,表示使用循环展开
- 指定展开最大深度:256
- 【build之后为:warp内部shfl reduce到shared memory中;一组thread继续读取shared memory进行shfl reduce,得到sum结果;】由于第二步计算得到了256元素,还需要reduce:继续开辟256个线程对256元素求和
@T.prim_func(private=True)
def mean(
A: T.Buffer((T.int64(2048), T.int64(8192)), "float32"),
T_divide: T.Buffer((T.int64(2048),), "float32"),
):
T.func_attr(
{"op_pattern": 4, "tir.is_scheduled": 1, "tir.noalias": T.bool(True)}
)
# with T.block("root"):
A_red_local = T.alloc_buffer((T.int64(2048),), scope="local")
A_red_rf_local = T.alloc_buffer((T.int64(256), T.int64(2048)), scope="local")
# sch: thread_binding
for ax0_fused in T.thread_binding(T.int64(2048), thread="blockIdx.x"):
for ax1_fused_1 in T.thread_binding(
T.int64(256),
thread="threadIdx.x",
# sch: unroll
annotations={
"pragma_auto_unroll_max_step": 256,
"pragma_unroll_explicit": 1,
},
): # 循环展开, (2048, 8192) -> (2048, 256) // 32循环展开
with T.block("A_red_rf_init"):
vax1_fused_1, v0 = T.axis.remap("SS", [ax1_fused_1, ax0_fused])
T.reads()
T.writes(A_red_rf_local[vax1_fused_1, v0])
A_red_rf_local[vax1_fused_1, v0] = T.float32(0)
for ax1_fused_0, u in T.grid(T.int64(32), 1):
with T.block("A_red_rf_update"):
vax1_fused_1, v0, vax1_fused_0 = T.axis.remap(
"SSR", [ax1_fused_1, ax0_fused, ax1_fused_0]
)
T.reads(
A_red_rf_local[vax1_fused_1, v0],
A[v0, vax1_fused_0 * T.int64(256) + vax1_fused_1],
)
T.writes(A_red_rf_local[vax1_fused_1, v0])
A_red_rf_local[vax1_fused_1, v0] = (
A_red_rf_local[vax1_fused_1, v0]
+ A[v0, vax1_fused_0 * T.int64(256) + vax1_fused_1]
)
for ax1_fused in range(T.int64(1)):
for ax0 in T.thread_binding(T.int64(256), thread="threadIdx.x"): # 求和
with T.block("A_red"):
vax1_fused_1, v0 = T.axis.remap("RS", [ax0, ax0_fused])
T.reads(A_red_rf_local[vax1_fused_1, v0])
T.writes(A_red_local[v0])
with T.init():
A_red_local[v0] = T.float32(0)
A_red_local[v0] = (
A_red_local[v0] + A_red_rf_local[vax1_fused_1, v0]
)
with T.block("T_divide"):
v0 = T.axis.spatial(T.int64(2048), ax0_fused) # 求均值
T.reads(A_red_local[v0])
T.writes(T_divide[v0])
T_divide[v0] = A_red_local[v0] * T.float32(0.0001220703125)
build之后:
rt_mod = relax.build(After, target)
source = rt_mod.mod.imported_modules[0].imported_modules[0].get_source()
build策略:
- 变量分配
- 循环展开
- shuffle
extern "C" __global__ void __launch_bounds__(256) mean_kernel(float* __restrict__ A, float* __restrict__ T_divide) {
float A_red_rf_local[1];
__shared__ float red_result[1];
# 1. 循环展开
A_red_rf_local[0] = 0.000000e+00f;
A_red_rf_local[0] = (A_red_rf_local[0] + A[((((int)blockIdx.x) * 8192) + ((int)threadIdx.x))]);
A_red_rf_local[0] = (A_red_rf_local[0] + A[(((((int)blockIdx.x) * 8192) + ((int)threadIdx.x)) + 256)]);
A_red_rf_local[0] = (A_red_rf_local[0] + A[(((((int)blockIdx.x) * 8192) + ((int)threadIdx.x)) + 512)]);
A_red_rf_local[0] = (A_red_rf_local[0] + A[(((((int)blockIdx.x) * 8192) + ((int)threadIdx.x)) + 768)]);
...
A_red_rf_local[0] = (A_red_rf_local[0] + A[(((((int)blockIdx.x) * 8192) + ((int)threadIdx.x)) + 7936)]);
# 2. sum: 第一次warp reduce -> 8
float red_buf0[1];
uint mask[1];
float t0[1];
float red_buf0_1[1];
uint mask_1[1];
float t0_1[1];
__shared__ float red_buf_staging[8];
red_buf0_1[0] = A_red_rf_local[0];
mask_1[0] = __activemask();
t0_1[0] = __shfl_down_sync(mask_1[0], red_buf0_1[0], 16, 32);
red_buf0_1[0] = (red_buf0_1[0] + t0_1[0]);
t0_1[0] = __shfl_down_sync(mask_1[0], red_buf0_1[0], 8, 32);
red_buf0_1[0] = (red_buf0_1[0] + t0_1[0]);
t0_1[0] = __shfl_down_sync(mask_1[0], red_buf0_1[0], 4, 32);
red_buf0_1[0] = (red_buf0_1[0] + t0_1[0]);
t0_1[0] = __shfl_down_sync(mask_1[0], red_buf0_1[0], 2, 32);
red_buf0_1[0] = (red_buf0_1[0] + t0_1[0]);
t0_1[0] = __shfl_down_sync(mask_1[0], red_buf0_1[0], 1, 32);
red_buf0_1[0] = (red_buf0_1[0] + t0_1[0]);
if ((((int)threadIdx.x) % 32) == 0) {
red_buf_staging[(((int)threadIdx.x) >> 5)] = red_buf0_1[0];
}
__syncthreads();
# 2. sum: 第二次warp reduce -> 1
if (((int)threadIdx.x) < 8) {
red_buf0[0] = red_buf_staging[((int)threadIdx.x)];
}
mask[0] = (__activemask() & (uint)255);
t0[0] = __shfl_down_sync(mask[0], red_buf0[0], 4, 32);
red_buf0[0] = (red_buf0[0] + t0[0]);
t0[0] = __shfl_down_sync(mask[0], red_buf0[0], 2, 32);
red_buf0[0] = (red_buf0[0] + t0[0]);
t0[0] = __shfl_down_sync(mask[0], red_buf0[0], 1, 32);
red_buf0[0] = (red_buf0[0] + t0[0]);
if (((int)threadIdx.x) == 0) {
((volatile float*)red_result)[0] = red_buf0[0];
}
__syncthreads();
# 3. multiply
if (((int)threadIdx.x) == 0) {
T_divide[((int)blockIdx.x)] = (((volatile float*)red_result)[0] * 1.220703e-04f);
}
}